CloudREST
An open architecture for connecting consumer IoT devices using RESTful APIs
Abstract
We live in a world where more and more of everyday objects embed computational capabilities, ubiquitous computing, a term coined by Mark Weisner in 1988, it’s a reality of our days. “Things that think”, smart things that are interconnected became what we call today the “Internet of Things” for which the industry and research principal concerns are transport of data to and from the “things” and the integration with the physical world. In the last years multiple vendors have begun to offer integrated solutions platforms to these concerns.
Services platforms like Amazon AWS IoT, Azure IoT Hub, Google Weave/IoT, TheThingsIO and others, offer turnkey solutions for connecting, managing and monitoring internet connected “things” and analyze and integrate data from them. While these service platforms greatly simplify the development and deployment of embedded devices, they are, for the most part, incompatible with each other, and require the knowledge of each mentioned platform.
In contrast, the Web highlights how well a set of simple and open protocols can be used to create powerful cross-integrations, flexible and efficiently scalable systems that are ubiquitously available on all kinds of devices. At the core of these integrations and flexibility is, usually, the Representational State Transfer (REST) architectural style. The service architecture that we propose in this paper builds on the premises of the REST architecture, but improves some of its shortcomings in “Internet of Things” scenario by being inspired by other available protocols and message formats.
While the above established service platforms focus on ingesting data from devices and then process and analyze it, our proposal shifts the focus to device accessibility and discovery while still being able to interconnect devices at a large scale. Exchanging and processing data at a large scale is a central concern for most of the existing solutions, that were designed to handle millions of switches, sensors and other simple devices but as hardware evolves a new breed of smart things emerge that have a lot of processing power and hardware capabilities packaged in a small package at a low cost. It is natural that these devices will have more software capabilities, and could process more data and take decisions depending on this data without relying in an external cloud architecture. With these kind of devices having a REST API endpoint makes more sense because it helps organize even a very complex system into simple resources.
Finally, we address the issue of local accessibility without internet access, which is not possible with any of the established solutions, as we believe that users should not be completely dependable on a cloud platform but able to operate their smart devices in any situation.
Contents
The Internet and Web of Things 11
Emerging trends in embedded hardware 12
MQTT - Message Queue Telemetry Transport 23
STOMP - Streaming Text Oriented Messaging Protocol 25
CoAP - Constrained Application Protocol 28
AMQP - Advanced Message Queuing Protocol 30
DDS - Data Distribution Service 30
XMPP - Extensible Messaging and Presence Protocol 32
Current IoT connectivity solutions 43
Basic Architecture Overview 48
Device Side - Connecting our device 49
Internal Software Architecture 49
Connecting to Server Side (Cloud) 51
Forwarding requests to device REST Service 52
Receiving notifications from on device application 53
Hardware and OS considerations 53
Device Factory Provisioning 54
Client Side - Controlling the device 56
Server Side - Where everything meets 57
REST API caching recommendations 71
Using REDIS to cache REST API calls on Server-Side 72
Client Notifications and Bidirectional Communication 73
WebSocket or HTTP/2 with Connections Pool. 74
Reducing number of REDIS queries 75
Open the Black Box: While most existing solutions, both “device” and “client” connect through a black box, research a open, real world architecture that is scalable and fault tolerant and would allow connecting lots of devices to lots of clients.
Not “Internet only”: As important as it is to access your device from anywhere in the world it’s as important to be able to access it locally though your local network, phone hotspot, bluetooth without being constrained to work through a cloud server or have a working internet connection. There are multiple examples of devices that fail to live up to their initial features because the “cloud part” no longer functions[1].
Promote interoperability and Web 3.0: Keep using REST. Currently most web services integrate using a REST API. It’s easier to design a REST solution than spending time to design a solution to work with vendor specific APIs.
No vendor SDK needed: Use widely available libraries, no extra vendor specific libraries on “device” or “client” applications.
No vendor lock-in: Use generic solutions and services that can be deployed on any IaaS platforms ranging from custom self made to “big players” in IaaS field: Amazon Web Services, Google Cloud Platform, Microsoft Azure. Promote the use of open protocols and open source software.
Promote client compatibility: The connected devices should be easily accessible from desktop, mobile and web browsers without the need of installing extra plugins.
The current research focuses on creating an open IoT architecture that promotes compatibility with existing Web standards and services. We also approach and solve the process of device identification and configuration that the device manufacturers meet during factory provisioning
The research presents solutions for local and cloud device discovery, and two alternative ways to authenticate with devices, one of which would permit storing the device password only on user device instead of cloud. This would protect against the famous “password database internet leaks” that happened to Yahoo[2], Dropbox[3], Linkedin[4] and Google[5].
Our research architecture is promoting the use of open-source technologies and vendor independent cloud deployments.
The comparison and benchmarks of different IoT protocols, message formats, and existing IoT services can be used in further researches.
Finally, we provide starting up code that is available on github address: https://github.com/nicupavel/cloudrest
Internet of Things is often described as a system of interconnected computing devices and smart devices. These devices can be anything from sensors, intelligent Heat Ventilation and Air Conditioning (HVAC), irrigation controllers, home appliances, identification tags and many more. There are many ways these devices can be classified by functionality, by industry sector, by size and computing power. For example Internet Engineering Task Force (IEEE) has one classification based on device computing power[6] and specify three classes.
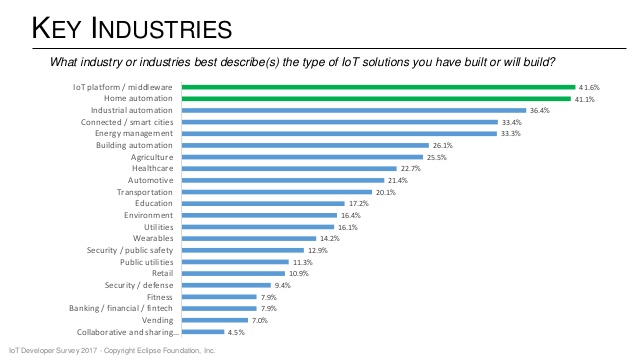
In IoT surveys conducted by Eclipse IoT Working Group[7], IEEE IoT[8], Agile IoT[9] and IoT Council[10] the devices are classified into Industrial Automation and Home Automation.
Throughout this paper we use the Consumer IoT terminology, as devices that are targeted to individual users of families with accent put on human interaction with the smart devices. Home automation devices makes up a large part of Consumer IoT, these are devices that user interacts frequently and want to integrate with other devices or web services.
While on Industrial IoT accent is put on transferring and processing high data rates, for Consumer IoT accent it put on accessibility and integration.
"This machine is a server. DO NOT POWER IT DOWN!!" it’s the text from a famous sticker on Sir Tim Berners-Lee, NEXTcube workstation, where he implemented and run the world's first web server, on a 25MHz processor and 16MB of RAM.
We came a long way since then, we are running web servers on systems with hundreds of CPU cores each at gigahertz speed, and terabytes of memory. Yet web servers do not require a lot of resources, we have implementations today that can run in very restricted environments with under 8KB of RAM and less than 10KB of storage.On the extreme side it is worth mentioning Smews[11] that can run with only 226 bytes of RAM, Miniweb[12] that uses around 30 bytes of RAM and uIP Web Server[13] that has bigger requirements (3KB RAM), but offers a scripting language for dynamic pages. So there is little reason an smart thing application to not include a REST server, if the application can run on the chosen hardware platform, adding REST functionality it will be a very small overhead.
As we will see next, the low power, embedded hardware platforms have evolved tremendously in the last decade and their computational speed can drive advanced 3D graphics, voice recognition and advanced application.
In recent years a growing number of companies have released embedded hardware platforms for the IoT world. These new platforms share some common traits:
We present some of the most used hardware platforms that are being used for implementing a new generation of IoT devices.
Released in September 2016, ESP32 is a low cost, low power system on a chip (SOC) microcontroller with integrated Wi-Fi & dual-mode Bluetooth, it sports a 240MHz dual-core CPU and 512KB RAM. Its built-in connectivity (WIFI, Bluetooth + Low Energy(BLE), Ethernet), sensors and very low power deep sleep state (5uA) makes it very attractive for creating connected smart things. On software side, beside the C/C++ frameworks and libraries, it can run eLua[16] or Python[17].
Image source: https://www.seeedstudio.com/ESP-32S-Wifi-Bluetooth-Combo-Module-p-2706.html
Specifications[18]:
Although MediaTek offers an array of system on a chip solutions, one interesting choice is the Linkit Smart 7688 which was released in December 2015. LinkIt Smart 7688 integrates a 1T1R 802.11n Wi-Fi radio, a 580 MHz MIPS 24KEc™ CPU, 1-port fast Ethernet PHY, USB2.0 host, PCIe, SD-XC, I2S/PCM and multiple low-speed IOs in a single SoC is designed especially for the prototyping of Rich Application IoT devices for Smart-Home[19].
The SOC offers sufficient memory and storage to enable robust video processing. Being a MIPS CPU it can run a Linux operating system distribution like OpenWRT. The platform also offers options to create device applications in Python, Node.js and C programming languages.
Specifications[20]:
With over 11 millions of units sold Raspberry PI is one of the most used boards by enthusiasts around the world. Released in February 2017 the PI Zero Wireless adds one of the most requested features, embedded wireless connectivity making Raspberry PI a very good choice for developing smart connected devices.
Image source: https://sites.google.com/site/jamesskingdom/Home/computers-exposed/the-raspberry-pi
Compared to the previous presented boards, this board it’s a powerhorse with 1Ghz ARMv6 CPU and 512MB of RAM. It has a performant GPU with OpenGL ES 2.0 acceleration and capable of decoding H.264 1080p videos. On software side there is virtually no restriction as the SOC is able to run any Linux operating system distribution as well as FreeBSD, NetBSD and Windows 10 IoT Core.
With previous boards we covered most of the CPU architectures that until now make up the bulk of Internet of Things devices, namely a custom microcontroller, MIPS and ARM architectures. Although x86 architecture didn’t make great inroads into IoT until few years ago with Intel Quark and Intel Edison platforms. In August 2016 Intel presented the Joule platform a ‘maker board’ targeted at Internet of Things developers.
Image source: http://linuxgizmos.com/intel-debuts-joule-iot-platform-with-ostro-linux-support/
The board features a quad-core Intel Atom running at 2.4 GHz, 4GB of LPDDR4 RAM, 16GB of eMMC, 802.11ac, Bluetooth 4.1, USB 3.1, CSI and DSI interfaces, and multiple GPIO, I2C, and UART interfaces. Coupled with Intel RealSense technology, it can be used in VR and AR applications as well as robotics or drone products.
Specifications[21]:
This sections provides various examples of consumer IoT devices built on the previously mentioned hardware platforms. For these devices we are interested on how well they are connected to various web services, the API or SDK offered and what hardware configuration is being used.
Google provides an array of cloud connected smart home devices the Nest Thermostat, Nest Smoke Alarm, Nest Camera. Nest Thermostat is a smart thermostat that controls and optimizes the Heat, Ventilation and Air Conditioning (HVAC) systems by learning owner schedules and local weather data. This allows for energy saving and cost reductions. The hardware is comprised by a ARM Cortex A8 processor, 512MB RAM, WIFI and Bluetooth with an built it display and rotary knob that allows local setup.
To fully use the thermostat features an active internet connection is required with an average monthly data rate of around 200 MBps[22] . It offers a REST API[23] with OAuth2 authentication that allows users to remotely control and get status updates from the thermostat.
The REST API is used in numerous available integrations with other external services like Samsung SmartThings, Wink, IFTTT a compressive list is available online on Works With Nest [24]page.
One downside is that It does not offer local network access (although requested by community[25]), all API calls are made through Google cloud services. The cloud service used for connectivity and REST API is Firebase[26] although initially it has used Amazon AWS services.
Wink Hub is a smart device which allows connecting and accessing third-party smart home devices associated with the Internet of Things, such as thermostats, door locks, ceiling fans, Wi-Fi-enabled lights, switches and outlets, in a single user interface. It can make smart devices without WIFI or internet connectivity, accessible from internet by having the ability to connect with wireless protocols like Zigbee, ZWave, Lutron Clear Connect, Kidde protocols and BlueTooth Low Energy.
Hardware wise it’s powered by a ARM9 CPU core at 454Mhz, 64MB DRAM and 128MB storage, including 5 wireless radios for the previously mentioned wireless protocols. It offers an extensive REST API[27] for controlling and monitoring the hub itself and the associated devices with authentication based on OAuth2 allowing integration with majority of third-party services. It’s also possible to access parts of REST API locally[28] [29] but official documentation lacks in this regard.
Belkin manufactures small and useful smart home appliances like wall outlets, light switches, light bulbs and cameras in a product range called Wemo.
Wemo doesn’t offer a REST API, and retired the use of the previously provided SDK due to security concerns. The remote access is only available on Wemo private servers with Wemo application. The Wemo devices don’t offer a web server but they are accessible by using uPNP[30] commands. With the retirement of official SDK the Ouimeaux: Open Source WeMo Control[31] community project is offering complete integration with Wemo products and offers a REST API for controlling the devices from the local network.
RainMachine is a smart irrigation controller, that gathers both forecast and measured weather information from multiple weather services and applies only the required amount of water necessary depending on plant types, soil and sprinkler heads resulting in excellent water savings and easy landscape care and management.
It’s available in two different hardware configurations an entry level version based on a 400 MHz MIPS processor, 64MB of RAM and 16MB of storage with a basic touch controls and led display and a high end version based on a ARM Cortex A8 at 800MHz, 512MB of RAM and 4GB of storage with high resolution touch display.
One interesting feature of these devices is that they are completely independent from any cloud service. All operations and simulation of future irrigation based on weather are done on device, all data being stored on device itself. A remote access service is provided through RainMachine servers, but local access is available on standard HTTP port.
RainMachine provides a comprehensive REST API[32] that’s available either on local network at port 8080 or remotely through https://my.rainmachine.com service. The REST API allows controlling and monitoring of all device functionality and allows integration with many third party service providers like IFTTT[33] or Amazon SNS[34] for push notifications.
When two entities need to communicate, they first need to agree on a protocol for communication, a set of rules that define the syntax, semantics, synchronization and error recovery. In network communication there are various levels in which communications take place, these levels have been standardized by the OSI model in a seven level model. For our implementation, we are dealing with protocol choices mostly at application level with a few incursions in the transport layer for the choice between TCP or UDP communication. In the table below we summarize existing choices for getting data from device to cloud servers and back on device. For each communication protocol we summarize various properties:
Protocol | RESTful HTTP(S) | RESTful HTTP/2 | WebSocket | CoAP | |
Transport | TCP | TCP | TCP | UDP | |
Payload | Text | Binary | Binary/Text | Binary | |
Architecture | Request/Response | FullDuplex Streams Multiplexing | FullDuplex Stream Channels | Request/Response Publish/Subscribe (OBSERVE) | |
QoS | N | Y | N | Y | |
Security | TLS/SSL | TLS/SSL | TLS/SSL | DTLS | |
Discovery | Y | Y | N | Y | |
Device - Device | Y | Y | Y | Y | |
Application Fields | real-time data sharing or real-time device control |
Protocol | MQTT | XMPP | AMQP | DDS | STOMP |
Transport | TCP | TCP | TCP | UDP/TCP | TCP |
Payload | Binary | Text (XML) | Binary | Binary | Text |
Architecture | Publish/Subscribe | Publish/Subscribe Request/Response | Publish/Subscribe | Publish/Subscribe Request/Response | Publish/Subscribe |
QoS | Y | Y | N | Y | N |
Security | TLS/SSL | TLS/SSL | TLS/SSL | TLS/SSL | TLS/SSL |
Discovery | N | N | N | Y | N |
Device - Device | N | N | N | Y | N |
Application Fields | telemetry or remote monitoring | distribute data to other devices |
Table 1: Comparison of most used IoT protocols
MQTT[35] was designed by IBM in the 1999 for low-bandwidth, high latency, unreliable networks as a lightweight publish/subscribe protocol with as minimal as possible bandwidth requirements. It runs on top of TCP stack and the publish/subscribe mechanism is asynchronous, making it suitable for IoT applications with there are lots of message updates that don’t need to be responded and the clients don’t have to poll for updates periodically as they receive those automatically, decreasing bandwidth requirements.
The MQTT publish/subscribe pattern requires a broker/server that holds an hierarchical structure of topics (eg: factory/sensors/sensor-1/temperature) created automatically when a client publishes or subscribes to a topic. The clients can use two types of wildcards, a single level wildcard “+” that matches everything string in that level (eg factory/sensors/+/temperature will select all sensors temperatures) and a multi level wildcard “#” that will match multiple levels (eg factory/sensors/# will match all sensors and all properties). It’s important to note that you can subscribe to a topic with wildcards but you can’t publish to them, each publish message must have a complete topic path.
The protocol is designed to be simple and it’s implemented using 14 message types, one fixed header and one header with variable size depending on message type to add only the minimum necessary overhead[36]. Possible message types are: CONNECT, CONNACK, PUBLISH, PUBACK, PUBREC, PUBREL, PUBCOMP, SUBSCRIBE, SUBACK, UNSUBSCRIBE, UNSUBACK, PINGREQ, PINGRESP, DISCONNECT.
A typical flow[37] for a message exchange without any quality of service is shown below:
The reliability of message exchange is provided by 3 levels of Quality of Service:
Both QoS level 2 and 3 have increased the bandwidth requirements and processing on both sides, with QoS level 3 requiring a four-way handshake to assure a one time only delivery, this is visible in the flow of QoS level 3 presented below:
The protocol has the ability to notify other clients about a client disconnect. Each client can set its own “Last Will and Testament” message that will be sent by broker if a client disconnects ungracefully.
On the security side, MQTT can use username/password authentication over a secure TLS/SSL connection.
STOMP[38] is a protocol designed to be lightweight and simple to implement by both clients and servers. It’s a text based protocol modelled after HTTP consisting in frames that contain command, a set of optional headers, an optional body ending with the null character.
A STOMP server is modelled as a set of destinations to which messages can be sent. The STOMP protocol treats destinations as opaque string and their syntax is server implementation specific. Additionally STOMP does not define what the delivery semantics of destinations should be. The delivery, or “message exchange”, semantics of destinations can vary from server to server and even from destination to destination. This allows servers to be creative with the semantics that they can support with STOMP.
A STOMP client is a user-agent which can act in two (possibly simultaneous) modes:
The protocol implements 10 message types (or commands):: CONNECT, SEND, SUBSCRIBE, UNSUBSCRIBE, BEGIN, COMMIT, ABORT, ACK, NACK, DISCONNECT.
The Quality of Service is limited to only client ACKing the message reception and the security is based on username/password with possible TLS/SSL transport (depending on server implementation)
When talking about RESTful HTTP as a communication protocol we refer to the HTTP/1.1 as the communication protocol while REST is an architectural style[40] that uses basic HTTP methods like GET, POST, PUT, DELETE to provide a resource oriented messaging system. Resources are referred by using Uniform Resource Identifier (URI) and the message payload is usually JSON or XML, but can also be raw bytes. Security is provided by the reliable HTTPs protocol using TLS/SSL and RESTful architecture can benefit from all the features of HTTP protocol like caching, content negotiation, extensibility via headers and authentication.
Since in a request/response architecture the Quality of Service makes less sense than in a publish/subscribe, QoS is not part of the HTTP protocol specifications but there are lot of QoS implementations in the web servers for rate limiting, bandwidth limiting, persistent connections and many more.
There are two big reasons why RESTful HTTP makes a compelling choice data communication. First is the fact that HTTP is the universal internet language, almost all services on the internet use an HTTP endpoint for integrations. Secondly sending and receiving data is very simple and all OSes and languages have an HTTP client and there are many choices for the server side. As we’ve seen on chapter 2.1 even the most constrained devices can run an HTTP server.
There are also two reasons why RESTful HTTP doesn’t make a good choice for IoT. First would be that message overhead is too big due to all headers that need to be sent and that the usual JSON or XML payload is too verbose. We show some ways to improve this in chapter 2.5 Device-to-Cloud Messaging Formats. The second reason is that the request/response architecture doesn’t perform great on IoT because of the constant polling needed to retrieve new data. While this is less of an issue with consumer IoT devices than with industrial IoT it’s still one of the problems that greatly affect performance.
There are a few choices to workaround this issue:
For resource discovery with REST we must note the Hypermedia As The Engine Of Application State (HATEOAS)[43] which allows REST application automatically discover resources as embedded in the responses received from server.
HTTP/2[44] is the next version of the HTTP/1.1 protocol, designed to address some of the mentioned shortcomings of the HTTP/1.1 protocol, but it is not a complete rewrite of the previous version of the protocol. This means that applications that use HTTP/1.1 will work with the new version[45]. As we presented in previous chapter the two issues with HTTP/1.1 namely message overhead and a nonexistent built in mechanism for pushing data to clients from server.
The HTTP/2 addresses both of this concerns, it has a 9 byte header, a resource friendly header compression, single TCP connection reuse and server PUSH for subscriptions. Also the messages are now delivered in a bidirectional stream and are binary framed which can be multiplexed. In contrast with previous protocol version, in which if the client wants to make multiple parallel requests to improve performance, then multiple TCP connections had to be used (called head of line blocking) the new binary framing layer in HTTP/2 removes these limitations, and enables full request and response multiplexing, by allowing the client and server to break down an HTTP message into independent frames interleave them, and then reassemble them on the other end. This is one of the most important addition to the HTTP/2 protocol the ability to interleave multiple requests and responses without blocking any one on a single TCP connection greatly improves the transfer speed, reduce latency and improve the utilisation of available network bandwidth without the need of multiple connections[46]. The server push mechanism available allow clients to receive response even if they hadn’t make a corresponding request this is done via a special frame called (PUSH_PROMISE). Clients can accept or reject (RST_STREAM) server push remaining in total control over the transmission.
The Quality of Service features present in HTTP/2 are available with two special frames (WINDOW_UPDATE and PRIORITY[47]). The client can increase the amount of data in flight by widening the flow-control window with WINDOW_UPDATE. Or, rather than telling the server to send more, the client can decrease the window to throttle back the connection. The server, in turn, can designate a stream ID with a PRIORITY frame, which allows it to send the most important resources first, even if the requests came in in a different order.
It is also noteworthy that the flow control options offered in HTTP 2.0 are defined to be hop-to-hop, rather than being between the server and browser endpoints. This enables intermediate nodes like web proxies to influence the throughput of the connection[48].
The security of the protocol is assured by the TLS/SSL[49] protocols but with some additions like Server Name Indication (SNI)[50]. Notable is the fact that earlier drafts of the HTTP/2 protocol mandate the use of TLS/SSL encryption but this is no longer the case[51].
CoAP is a protocol that runs over UDP to minimise the overhead usually associated to TCP connections. The protocol is modeled after HTTP with a RESTful architecture by using the GET, POST, PUT, DELETE commands to interact with URI indicated resources in a request/response pattern. This pattern has been extended with an Observe[52] pattern that function like a long timed GET which is used in client as a mechanism to receive the resource content when it has changed on server. Protocol supports both synchronous and asynchronous responses and has possibility to send multicast messages to a group of devices[53].
Because running over UDP is unreliable for most cases CoAP implements its own Quality of Service to achieve reliability several messages types[54]:
Duplicate detection is performed using a the message ID that is a 16 bit header field for each CoAP packet.
Message size is restricted by the size of the underlying link layer packets[55] which usually is around 1024 bytes, but can as lower as 60 bytes for 6LoWPAN networks, for larger transfers the BLOCK extension must be used that enable block-wise transfers[56].
The protocol doesn’t offer any built in security but relies on another protocol specification named Datagram Transport Layer Security (DTLS)[57] which runs on top of UDP similar to how TLS works for TCP.
WebSocket[58] is a protocol directly implemented over TCP sockets that enable bidirectional communication over a single TCP connection. It was introduced as part of HTML5 initiative with the purpose to facilitate real-time streaming communication on the Web.
The protocol uses HTTP for handshake using an upgrade header[59] which allows WebSocket to work over firewalls. After the handshake has been performed the protocol no longer uses HTTP headers and the messages are sent in a two-way communication channel where each side can independently from the other, send data at will[60].
Messages are split in frames with a small overhead of 31 bits and can be of two types: control frames and data frames. Data frames can contain payload in either binary or text format depending on a value of a bit in frame[61]. The protocol specification defines ws:// and wss:// as two new uniform resource identifier (URI) schemes that are used for unencrypted and encrypted (with TLS/SSL) connections, respectively. Apart from the scheme name and fragment (# is not supported), the rest of the URI components are defined to use URI generic syntax[62].
There is no Quality of Service levels in protocol specifications and it relies only on reliability of TCP.
If initially WebSocket was deemed impractical on resource constrained devices, recently new implementations like cwebsockets[63] and libwebsockets[64] are capable on running even on Expressif ESP32[65]. This made websocket the default transport protocol for MQTT[66], AMQP[67], STOMP[68] or DDS[69] protocols over web.
The AMQP[70] protocol is designed for enterprise environments with focus on reliability, interoperability and security.
It provides many advanced features like asynchronous publish/subscribe topic messaging with reliable queueing, routing, transactions, per queue security and limits, message send and receive rules and store-and-forward for network disruptions. The security is provided by the use of TLS/SSL protocols.
The quality of service is ensured with 3 types messages similar to MQTT QoS levels[71]:
DDS[72] is a publish/subscribe protocol that is quite different that other protocols primarily because it doesn’t need a broker, the protocol is best described as a connectionless, decoupled communication that is best when not all data needs to be centralised as it directly addresses real-time systems. DDS is a data-centric protocol and it understands the contents of the information it manages, can automatically serialize/deserialize data and manages the communications data model, or types used to communicate between endpoints. Participants are either publishers of data, or subscribers to data and system has no hard-coded interactions between applications. DDS automatically discovers and connects publishing and subscribing applications. No configuration changes are required to add a new smart machine to the network and matches and enforces QoS. DDS overcomes problems associated with point-to-point system integration, such as lack of scalability, interoperability and the ability to evolve the architecture. It enables plug-and-play simplicity, scalability and exceptionally high performance[73]
Like aforementioned AMQP, DDS it’s a complex protocol it can selectively run on both UDP (unicast or multicast) or TCP. By default on local networks and for discovery process, it uses UDP but for connecting networks, or device to cloud communication it uses TCP[74].
The QoS policies available in DDS protocol are very complex but it’s one of the most important features of the protocol. The policies are grouped by delivery scope and data scope.
Scope | QoS Policy |
Volatility | DURABILITY |
HISTORY | |
READER DATA LIFECYCLE | |
WRITER DATA LIFECYCLE | |
LIFESPAN | |
Infrastructure | ENTITY FACTORY |
RESOURCE LIMITS | |
Delivery | RELIABILITY |
DEADLINE | |
CONTENT FILTERS | |
User QoS | USER DATA |
TOPIC DATA | |
GROUP DATA | |
Presentation | PARTITION |
PRESENTATION | |
DESTINATION ORDER | |
Redundancy | OWNERSHIP |
OWNERSHIP STRENGTH | |
LIVENESS | |
Transport | LATENCY BUDGET |
TRANSPORT PRIORITY |
We can exemplify some QoS policies scope mappings when sending data as follows[75]:
Continuous Data:
– Constantly updating data – best-effort
– Many-to-many delivery – keys, multicast
– Sensor data, last value is best – keep-last
– Seamless failover – ownership, deadline
State Information:
– Occasionally changing persistent data – durability
– Recipients need latest and greatest – history
Alarms & Events:
– Asynchronous messages – liveliness
– Need confirmation of delivery – reliability
XMPP protocol[76] was originally designed for near real time instant messaging based on XML format by the Jabber open source community in 1999. XMPP runs over TCP and has a asynchronous publish/subscribe architecture but can also function in a request/response synchronous mode. It runs over TCP but the community developed a HTTP transport for the web clients that exchange XML messages called “stanzas” which fall in three categories:
Messages are delivered based on client JID which is structured like an email address but which can specify a resource: user@domain/resource. Recently protocol has gained a lot of attention in IoT field[77] with lightweight implementations like microXMPP[78] and XMPP mbed client[79]. This sprung a lot of new extensions to the protocol that address its shortcomings like missing QoS[80], HTTP polling[81] and extends applicability in IoT like Sensor data[82], Control[83], Provisioning[84] and Discovery[85].
With the mentioned extensions protocol can offer 3 levels of QoS similar to those of MQTT, and can do Delayed Delivery[86] for offline clients. For security it uses TLS/SSL on par with mentioned protocols.
To compare the mentioned protocols we must first establish what are the features that we’re interested on. Firstly we are interested in services interoperability, hardware compatibility and current industry adoption as published in surveys from 2015[87] and 2016[88]. Then we are interested in the future trends of this industry adoption. For this we use the results published in 2017 on the IoT Developer Survey[89] sponsored by Eclipse IoT Working Group, IEEE IoT and AGILE IoT. Secondly, we look at what performance we can expect from the protocol and their field of use for which we use several research papers that compare IoT protocols performance. Lastly, we look at protocol offered security and how easily is to pass data through a firewall
For consumer IoT devices interoperability usually means integrating your device with services like IFTTT[90] to perform various tasks in connection with other web services, or integrate with a smart assistant like Amazon Alexa and Google Home, or an alert or messaging service like Twitter. For industrial IoT devices it might be important to store your data in cloud with a service like Google Storage,Google Firebase or in a database like Amazon DynamoDB. All these services usually offer a REST API, making HTTP protocol the perfect choice, all other protocols requiring at least one more transforming step. As an example for integrating with IFTTT you need to provide IFTTT the REST API endpoints for your service (or device) like OAuth2 URL, Triggers endpoints (which will be polled by IFTTT for changes) and Actions endpoints (to execute commands on your device). If device/service is using a REST API this is quite straightforward. In contrast if your device uses MQTT a separate layer is needed that builds necessary REST API endpoints and then processes requests and publishes corresponding messages to corresponding topics.
If you need to access a device/service from browser again HTTP is the clear winner with WebSocket being second. Although it’s possible to tunnel other protocols through HTTP using WebSocket in browser this is usually not as straightforward.
For example, MQTT has a JavaScript browser client[91] that can connect to a broker directly from browser and it’s built on top of WebSocket. XMPP can be built on top of HTTP but some extensions are implemented using websockets[92]. Similarly, STOMP can communicate in browser using WebSocket[93] protocol. In general MQTT, XMPP and STOMP have programming languages bindings for most currently used languages. Being UDP based CoAP can not be implemented currently in browsers (although a Firefox extension exists[94]) but has several programming languages bindings.
AMQP has a WebSocket binding specification[95] but the existing implementation[96] is currently designed to go through a 3rd party server (although it’s possible to modify it to remove this requirement). Other languages bindings are well represented[97].
Being the newest protocol from the previously mentioned one DDS has less language bindings and usually bindings are created by using the RTI Connext DDS[98] library through different methods[99].
For embedded devices most protocols offer lightweight implementations. HTTP, WebSocket[100], CoAP[101] , MQTT[102] and AMQP[103] have existing open-source implementations that can be used with or without an OS in a firmware like mode on devices similar with ESP32. DDS offers a proprietary closed source solution[104].
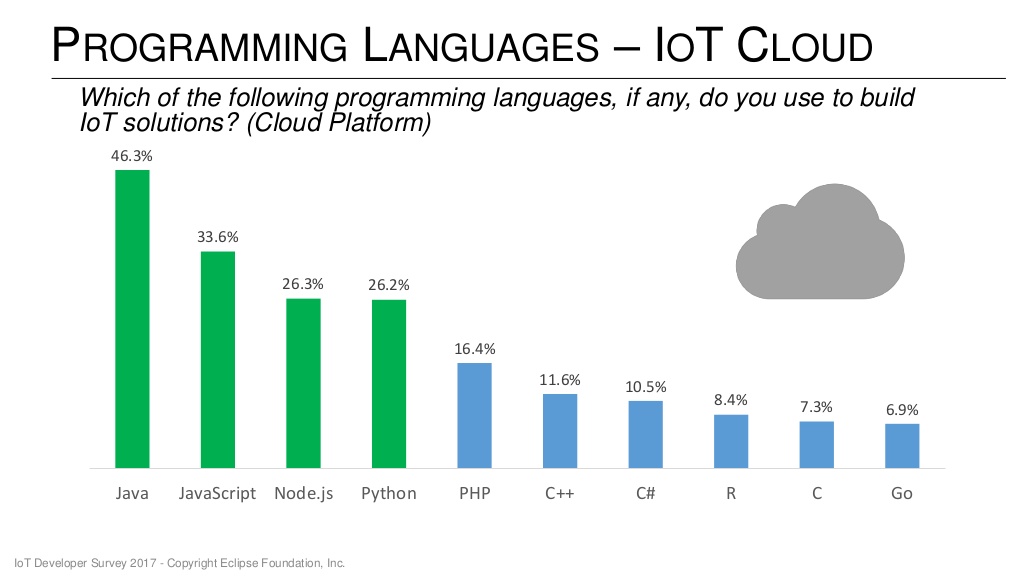
When comparing with IoT Developer Survey results, for programming languages on constrained devices all protocols have bindings for top 3 languages.
Same can be told about the survey results for programming languages on the cloud side of IoT although HTTP, MQTT, CoAP, AMQP are generally better represented.
Comparing performances of the protocols it’s a daunting task because each protocol has been designed for a certain architecture or field.
For example, MQTT makes more sense in industrial IoT field where you need to centralize data from ten of thousands of sensors on a central server for further analysis, and doesn’t need to be fast with acceptable latencies measured in seconds. AMQP can do the same but makes sense in an architecture where there isn’t necessarily a central server but you need to report sensor readings to several servers each belonging to a different organization. This is extensively compared in the white paper “A Comparison of AMQP and MQTT”[105] .Their show matching performance under unstable networks as tested in “A comparative evaluation of AMQP and MQTT protocols over unstable and mobile networks”[106] .
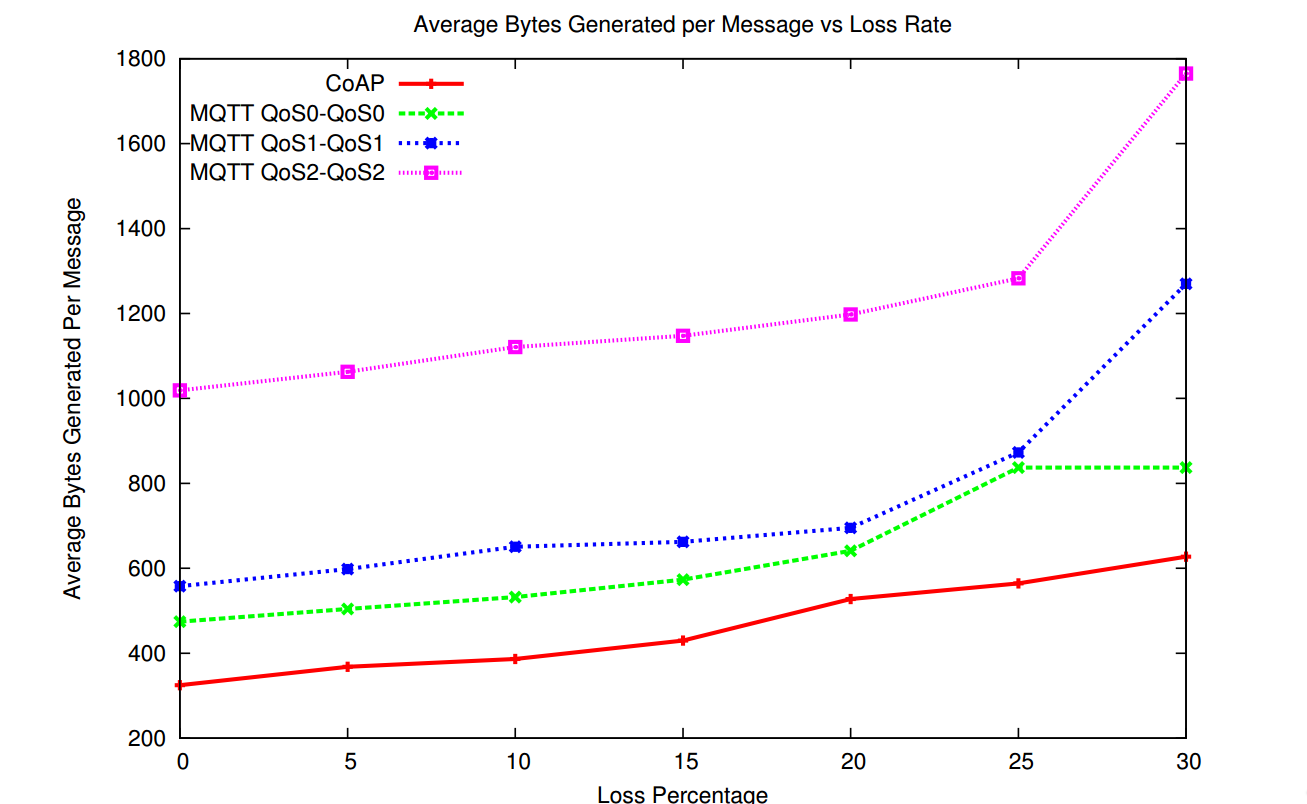
CoAP is better for local control with actions like flipping one or more switches on/off, it can use it’s multicast feature to control all lights on your house but multicast feature cannot be secured with DTLS. In “Performance evaluation of MQTT and CoAP via a common middleware”[107] authors concluded that MQTT experienced lower delays than CoAP for lower packet loss and higher delays than CoAP for higher packet loss and when the message size is small and the loss rate is equal to or less than 25%, CoAP generates less extra traffic than MQTT to ensure reliable transmission.
In contrast to above protocols, HTTP is not well suited to send multiple commands as each command must setup a connection, send data and wait for a response. Without Long-polling or Server-Sent-Events, HTTP performs mediocrely if used to constantly receive data but it is excellent choice to transfer large historical data from devices.
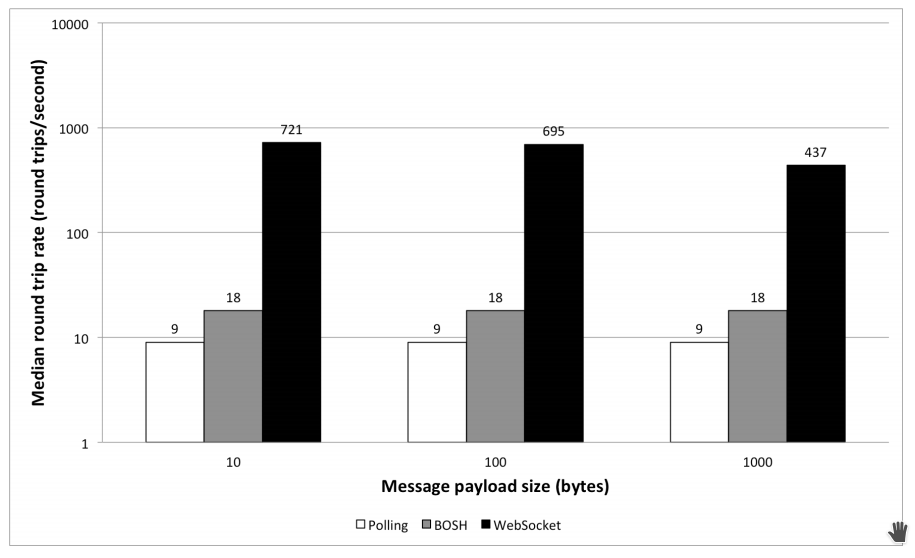
An interesting study is “Performance Evaluation of XMPP on the Web”[108] that
although focuses on XMPP over the web it actually compares Long-Polling and WebSockets by using two metrics. One is sending a message to self through a server and measuring round trips per second and second is message rate per second. In round trip test WebSocket has dramatic performance improvements while on the second the performance is almost equal concluding that when used properly HTTP can attain high messages rates although the need to create new connection is the protocol biggest performance limit.
Another interesting study is “Performance evaluation of RESTful Web services and AMQP protocol” [109] that compares RESTful web services with AMQP publish/subscribe architecture. In the test conclusion, AMQP could achieve rates of 211 messages per second while REST only 125 messages per second.
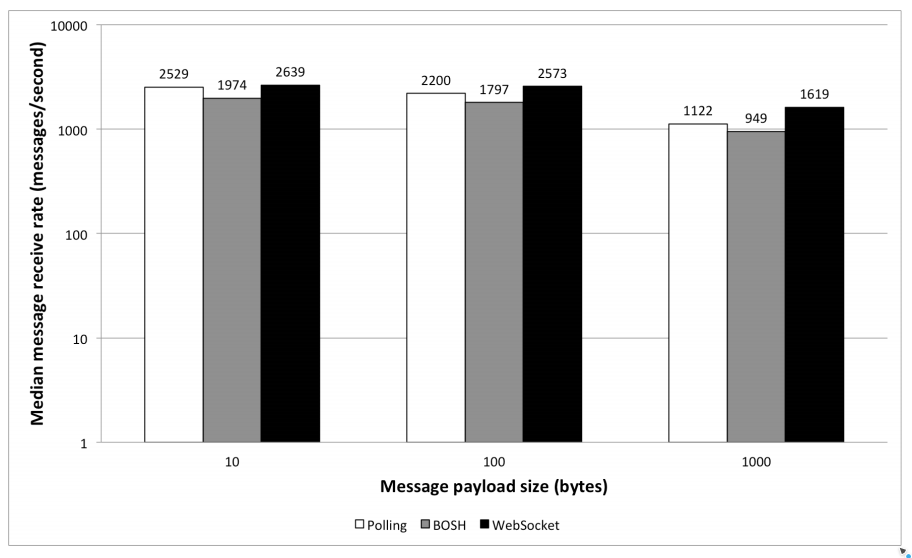
Finally, we want to highlight “Web Performance Evaluation for IoT Applications”[110] a compressive performance evaluation of previously mentioned protocols. It a very valuable resource as it compares Long-Polling HTTP, WebSocket but also MQTT, AMQP, XMPP and DDS. In the results with a 7KB payload they obtained the following results:
It’s worth noting the difference in slopes of the two regressions for the small payload (1.5KB) and larger payload (7KB). With small payload HTTP has more than twice latency than MQTT, but latency differences decrease as we increase the payload. For consumer IoT, we expect larger payloads with less changed messages than industrial IoT with small payloads, frequent changed messages updates.
As protocol security all protocols can use TLS/SSL with the exception of CoAP which uses DTLS which can’t be used in conjunction with CoAP multicast.
When considering how easily a protocol can pass through a firewall, HTTP is the clear choice followed by WebSockets (which works as a HTTP protocol upgrade command). XMPP, MQTT, AMQP, DDS with TCP/IP might require special ports being opened unless they are built on top of WebSocket protocol. UDP protocols like CoAP will have the most issues passing firewalls as most firewalls block outgoing UDP packages.
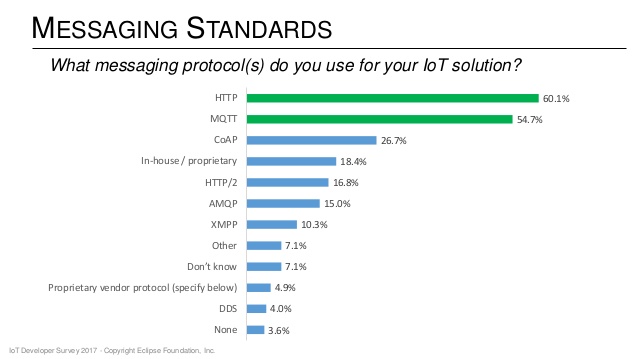
For current and future industry protocol adoption, as published in 2017 IoT Developer Survey, we have HTTP and MQTT at the top of the list with HTTP a slight advantage (60.1% vs 54.7%).
Considering the above performance tests and interoperability benefits, HTTP is a better choice for our architecture. When choosing HTTP we are also taking into account the next version of the protocol, HTTP/2 which solves most of the bottlenecks present in version 1.1 of the protocol. As the protocol gains more traction in most of the web servers and browsers our architecture can be easily updated to the new protocol version. Already HTTP/2 is used in Google gRPC[111] project in conjunction with a gRPC server for high performance remote procedure calls.
The communication protocols presented above usually carry a payload data that can be in different formats with certain syntax either text based or binary. These formats are called data inter-exchange formats which basically is a translation of data structures and objects state into a format that can be transmitted over the network and reconstructed in on the other receiving end. This process of translation is usually called serialization or marshalling.
For web and RESTful services, most commonly used are Extensible Markup Language (XML)[112] and JavaScript Object Notation (JSON)[113] which are text based formats. For IoT there are both benefits and disadvantages for using these formats. Lately JSON became mainstream as it is perceived as a more compact format, easier to read and it can be natively (or naively) understood by browsers and JavaScript applications (Note: verbosity and readability is arguable: JSON { “person”: {“age”: 40, “height”: 180}} 52 characters vs XML <person age=”40” height=”180”/> 40 characters)[114].
IoT devices can include in their messages semantic resources described using Resource Description Framework (RDF)[115] to implement intelligent and automated services to express concepts and their relations and describe ontologies for which data belongs. Like the messages, RDF data can be expressed either in XML (RDF/XML), JSON (RDF/JSON) or other formats. Currently, there is still no standard on how to represent IoT resources or data and these can be effectively searched and combined although several research studies have proposed solutions for this[116] [117].
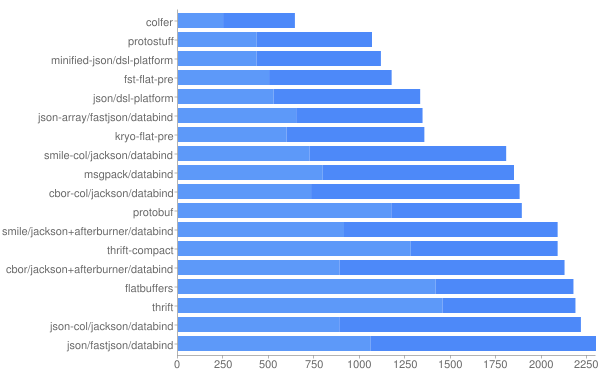
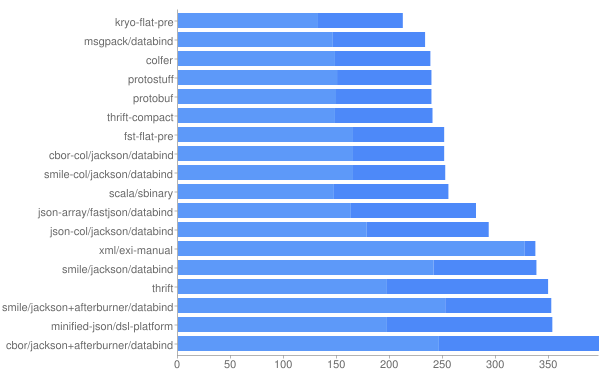
The disadvantages of using either JSON or XML is their verbosity compared to a binary serialization and encoding/decoding speed issues in most programming languages (except JavaScript for JSON). In the recent years, a plethora of binary data inter-exchange formats have appeared that improve size and speed. On JVM Serializers Benchmark page[118] there are roughly 30 formats compared. To enumerate a few these are MessagePack[119], Google Protocol Buffers[120], Google FlatBuffers[121], Facebook Thrift[122], Apache Avro[123], Cap’n’Proto[124].
Beside size and speed improvements most of the formats also include the possibility to perform Remote Procedure Calls (RPC) over various protocols, schema for accessing data without parsing, validation and strong typing.
As a small example how they work we look at the most simple format, Message Pack which transforms a 27 bytes JSON:
{ “compact”: true, “schema”: 0}
to 18 bytes MessagePack format:
82 | A7 | c | o | m | p | a | c | t | C3 | A6 | s | c | h | e | m | a | 00 |
Where 82 means a 2 element map, A7/A6 a string with 7/6 characters, C3 is the true value, 00 is the integer 0.
Looking over the benchmark results[125] the benefits of fast serialization/deserialization are small with JSON being the third overall.
The size benefits are more consistent top performers are able to reduce by 50% the JSON size.
Most formats either require that you define data scheme beforehand or work on transforming JSON and – since we are building a generic architecture that will connect different devices with different RESTful APIs (that can be in XML, JSON or something else) – we cannot use serializers to reduce message payload. On the other hand, we could use them for different control messages from device to cloud and vice-versa or data caching.
For message payload size reduction we can use standard HTTP compression[126].
In 2017 IoT Developer Survey, developers were asked what cloud service offerings they use or plan to use to implement their IoT Solution. Nearly 43 percent of those replied that they use Amazon AWS while Microsoft Azure and Google Cloud Platform had around 20 percents. Comparing to 2016 survey the developers considering a private/on-premises IoT solution deployment has decreased from 35% in 2016 to only 18% in 2017. This doesn’t mean however that developers will necessarily use the IoT solutions provided by Amazon, Microsoft or Google but that they will deploy their infrastructure to these vendors.
In the next chapters, we present the actual IoT platform and services offerings by the top 3 vendors. We note that none of the presented platforms make any effort on exposing an existing device REST API to the internet and are more concerned to ingesting the data and processing it with other services available on their platforms.
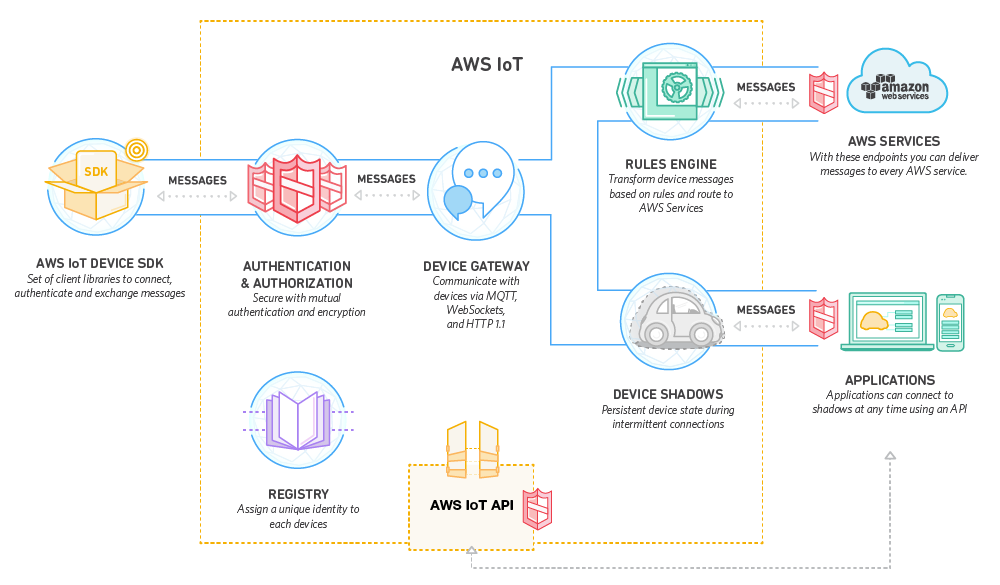
Amazon AWS IoT is a platform for building complete IoT solutions on AWS. Each IoT project gets a connection endpoint on which devices can communicate securely and bi-directionally with the cloud. AWS IoT is built on top of MQTT protocol and the connection endpoint is actually a MQTT broker.
Image source: https://aws.amazon.com/iot-platform/how-it-works/
Devices can connect to the IoT endpoint with a certificate/key pair using either plain MQTT protocol or MQTT over WebSocket and can publish/subscribe to topics they need. HTTPS protocol is only using for pushing data to a topic.
Besides the custom topics that devices can publish/subscribe, AWS IoT also creates reserved topics for each device to simplify management and monitoring.
Some of these topics represent the “Things Shadow”. Each device is represented by one or more “things shadows” which are JSON documents (limited to 8KB) that represent state or other information for a device. The shadows are also used to communicate with the device with a RESTful API even when device is offline, data will be sent to device when it comes back online. AWS IoT automatically optimize data sent to a shadow by only sending the differences between the actual published state and the changed parameters.
“Rules engine” is another powerful feature of AWS IoT. Developer can create multiple rules with a SQL syntax and route messages for selected topics to different services in AWS like DynamoDB, Kinesis Streams/Analytics or execute a Lambda function. Rules can select topics, part of topics or certain fields in the data and can have multiple actions.
“Device Registry” organizes the resources associated with each thing including certificates and MQTT client connection ID for easier management.
On device side Amazon IoT offers SDKs for most commonly used languages (C, Java, JavaScript, Python) and Arduino Yun. For mobile applications SDKs for Android and iOS are available[127].
There are several limits on AWS IoT related to number of inbound (3000/s) and outbound messages(6000/s), topics are limited to 7 slashes, maximum size of data published is 128KB with a total of 512 KB/s per connection limit and a maximum of 50 subscriptions per connection. This limits might make it difficult to implement a mesh of sensors that send data through 1 gateway (connection) to AWS IoT.
“Things shadows” are difficult to maintain, each shadow must be created beforehand with the AWS IoT REST API with an unique name limited to 128 characters. For devices with extensive features commonly found on Consumer IoT devices, the developer must split these features in several “things shadows” due to JSON size and depth restrictions. This complicates the REST API, management of device features, and of devices in general.
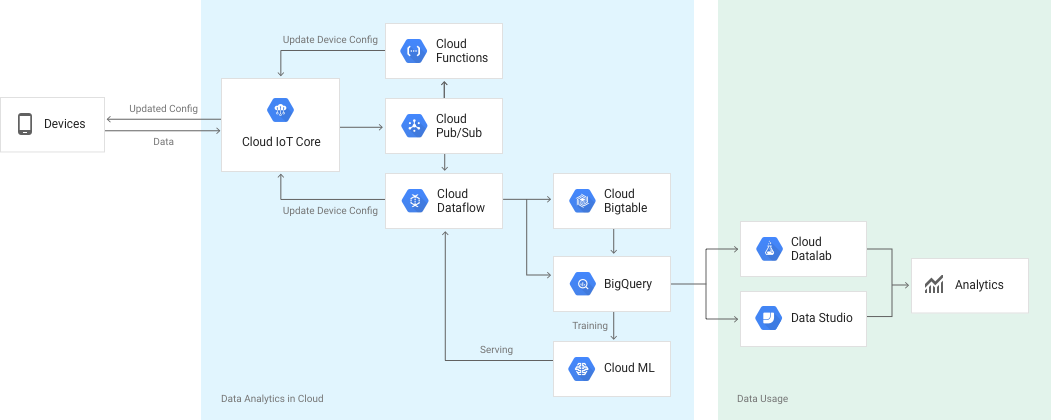
Google IoT offerings had changed several times in recent years. Most recent solution Google IoT Core[128] is currently in private beta as of June 2017. But Google does offer other solutions like Google Pub/Sub and Google Weave. We’ll take a look at Google Weave which is a complete IoT solution device and server side.
Image source: https://cloud.google.com/solutions/iot/
Google Weave is comprised from two parts: on devices - weave client (or libiota) and a cloud component weave server. Beside these two basic components Google offers integration services with google services, a monitoring and management console and companion client/mobile apps.
Google Weave is using gRPC[129] for high performance data transfers between device and cloud and claims over 3 times performance gains[130] vs standard HTTP/1.1 REST API. This is due to the fact that gRPC is using HTTP/2. gRPC is not using a RESTful API but instead sends commands along with parameters and other flags in a JSON format to the device.
As messages enter Google Weave server (based on Google Pub/Sub) rules can be configured using Google Cloud Dataflow to perform different actions and route to other Google services in real time, a feature similar to AWS IoT Rules engine.
An interesting feature of Google Weave is that it tries to solve the incompatibility between IoT devices by using Device Traits and Devices Schemas. Traits are properties of devices like brightness for a lightbulb or temperature for a Heat Ventilation and Air Conditioning (HVAC) system. Devices Schemas bundle specific device traits and commands into special categories.
Currently Google defines four devices types (Light, Wall switch, Outlet and HVAC controller). With these standard schemas, users can build a mobile app easily and have a default interface to control device traits. The downside is that more complex devices must use one of the standard schemas and add other traits which might not be entirely possible.
To use the Google Weave IoT ecosystem, devices must be certified by Google, actually the device firmware must be sent for inspection and certified[131] as well as any future updates must go through same process.
Another downside that we observed when assessing Google Weave is that we were unable to compile the device library for MIPS platform or under OpenWRT[132] Linux distribution. That was because weave library uses some C++14 extensions that aren’t widely available on embedded distributions lightweight libraries.
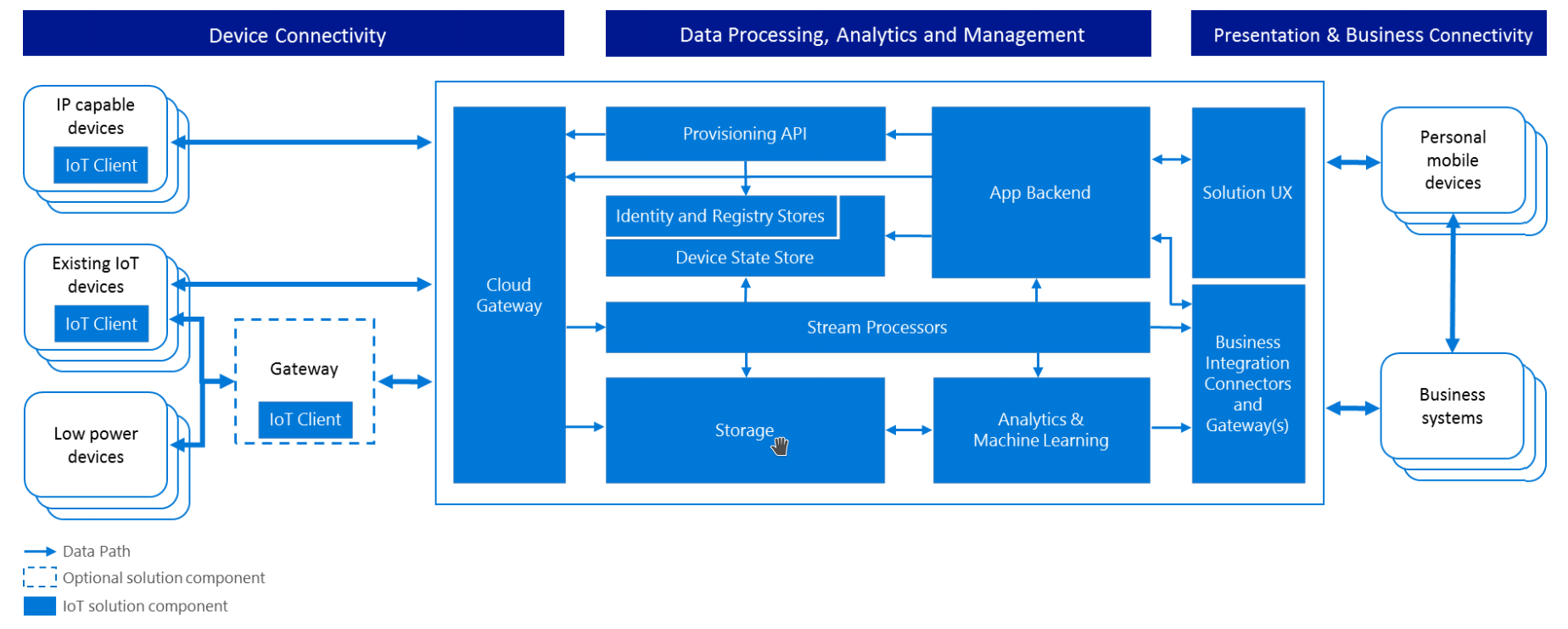
Microsoft Azure cloud platform offers IoT Hub, a managed IoT solution that offers bidirectional communication through HTTP, AMQP, MQTT and MQTT over WebSocket protocols.
Image source: https://azure.microsoft.com/en-us/updates/microsoft-azure-iot-reference-architecture-available/
For devices that can’t directly connect to the internet or that can use the above protocols Microsoft offers an open source SDK called Azure IoT Protocol Gateway[133].
Like the AWS and Google solutions, Azure IoT Hub can offers a rule engine, Azure Stream Analytics , with an SQL like syntax, that can route incoming messages to other Azure Cloud services.
The REST API for accessing devices is done with “Device Twins” which is similar to “Device Shadows” feature of AWS IoT, a complicated solution that requires a REST API SDK to simplify the operations but which is only available for .NET and Java[134]. We note is that in contrast with AWS IoT, Azure IoT Hub doesn’t allow direct publish/subscribe to MQTT/AMQP topics, all interactions need to be done through their supplied SDKs. Also Azure IoT Hub does not have, yet, a service like AWS Just in time Registration[135] to greatly simplify the process of factory provisioning of devices with certificates to allow connectivity out of the box.
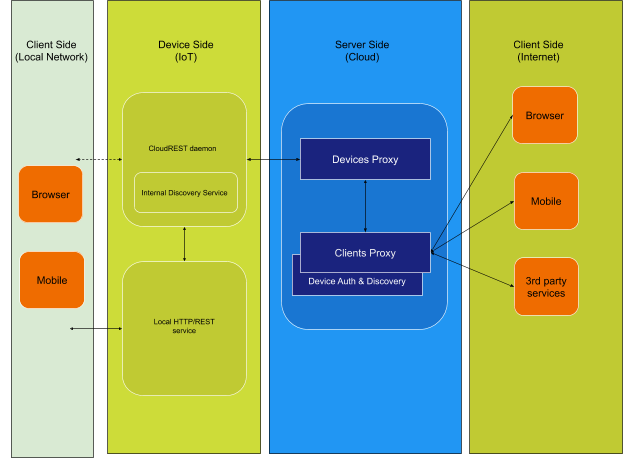
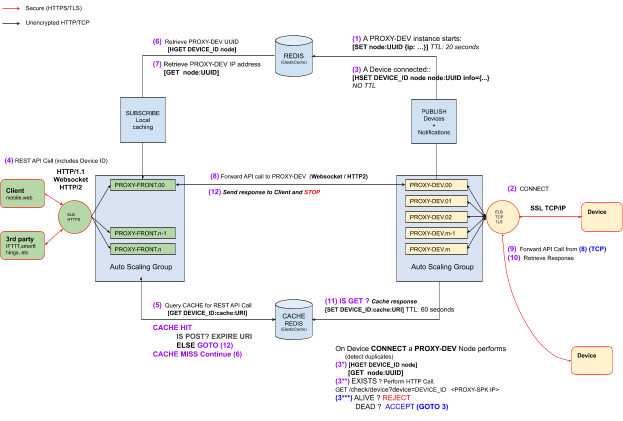
We need to simplify the entire process of getting a smart device connected and accessible from internet. Device manufacturers will only need to develop their product to respond to RESTful API queries and then build and install CloudREST daemon which will take care of interactions with the cloud. It’s also possible that CloudREST daemon also handle the Local Network interaction although we haven’t yet implemented this scenario.
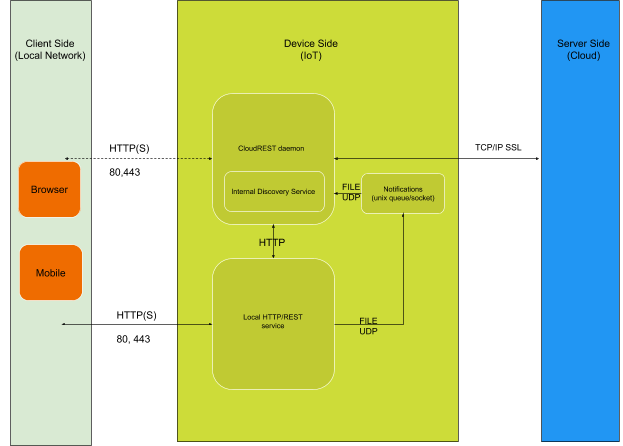
The architecture that we propose is summarised in the below figure. There are four sides involved: Local Network from which clients can connect directly to device, Device Side summarizes the process running on the device itself, Server Side the services that run on cloud servers and clients and other web services that connect from Internet Side.
As a general overview of the “on device” architecture, there are two important pieces,
the REST server a service provided by the device developer/manufacturer and the CloudREST daemon (shortly referred as daemon throughout the document). CloudREST was designed to run as a daemon on device, but the code can be adapted and used as a library in the manufacturer supplied REST service.
The developer of the REST service need to implement to the following requirements:
{
“name”: “device name”,
“manufacturer”: “manufacturer name”,
“version”: “device version”,
“revision”: “hardware revision”,
“api”: “REST API version”,
“apiAuthPath”: “resource to call for auth with device”,
“apiFactoryConnect”: “resource to call for connecting device to factory”,
“email”: “user email set on this device for accessing it on internet”
}
Other fields present in this JSON will be sent to server unmodified.
Internally, CloudREST daemon has 4 components:
There is also the intention to make CloudREST daemon listen for HTTP(S) requests on local network on port 80 or 443 similar to a HTTP server and forward these requests to internal REST service. This will free the REST service developer from dealing with a SSL implementation and also has other benefits like expiring cached documents on cloud server when modifications are done from local network.
The CloudREST daemon opens a TCP/IP SSL connection to the server with hostname specified in command line arguments using OpenSSL library. If connection is successful it sends to the server the device ID along with the other information present in the JSON obtained from REST service. The server checks if the device ID exists in server database and terminates the connection if ID is unknown. While connected client waits for messages from server and if they are of http request type it creates a HTTP connection to local REST server and sends the message. When the response comes from the local REST server it sends this response to server.
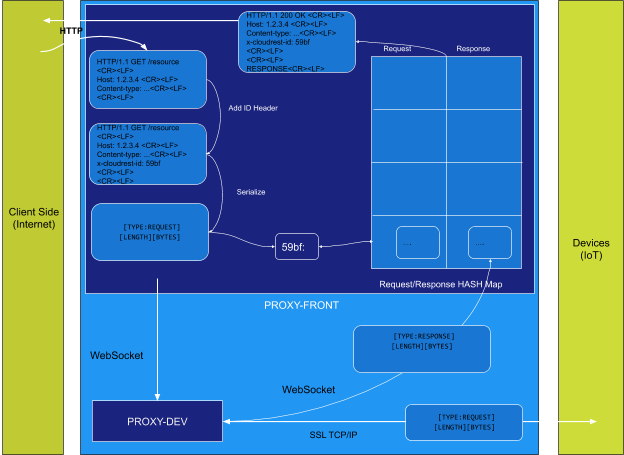
To simplify the data communication, we defined a custom protocol to serialize the messages sent or received from server. The protocol message format is:
TYPE (1 byte) | LENGTH (4 bytes) | CONTENT (LENGTH bytes) |
TYPE defines the message type and in the minimal implementation has these values:
Type | Value | Description |
CONNECT | 1 | Sent by client when connecting this message has device ID as content |
CONNECT_ACK | 2 | Sent by server if device ID is valid |
HTTP_REQUEST | 3 | A HTTP request received from cloud connected clients. Sent by server to device which will forward it to internal REST service. |
HTTP_RESPONSE | 4 | A HTTP response received from the REST Service. Sent by device to server |
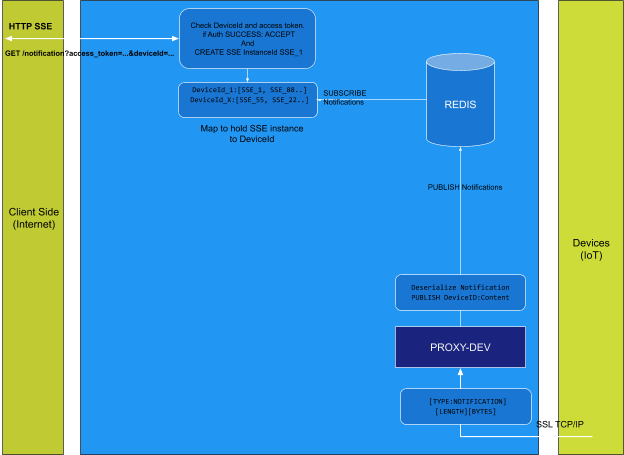
NOTIFICATION | 5 | A notification string received on unix named pipe/socket. Sent by device to server. |
Once a message with type HTTP_REQUEST is received by the daemon, it will be sent to localhost REST service. For this we are using libcurl a highly portable client side transfer library[140]. Once the response is received we send it through server socket packed with message type HTTP_RESPONSE. If any error occurs we are still generating a HTTP_RESPONSE message for compatibility reasons.
There are two performance considerations when forwarding requests to local REST service:
The daemon can also offer a simple discovery services, which can be used by mobile apps to detect the devices and their REST API URLs on local network. It works by listening on UDP BROADCAST network address port 15800 for messages. Client applications on local network can send a dummy message to this BROADCAST port 15800 combination and expect a text response on port 15900 with the content:
CloudREST || <Device MAC Address> || <Device Name> || <REST API URL>
The daemon also offers a possibility to send unsolicited messages to the cloud server. When daemon is started on system boot, it creates a unix named pipe in /tmp folder using mkfifo() function then opens it in nonblocking mode for reading and writing. This pipe is used for simple message FIFO transfer between the on device application and CloudREST. The device application developers must open this file in writing mode and write strings separated by new lines. This strings will be sent on cloud server and can be used, for sending push notification messages to clients.
We tested the daemon under ARM Cortex A8 CPU and AR933x MIPS CPU, and 32 MB of RAM memory. The daemon was successfully compiled under Ubuntu Linux, OpenWRT Linux using uClibc and uClibc++ [141] standard C libraries and Android 4.3 using bionic standard C library[142]. Currently, the daemon requires the following libraries to be available on target system:
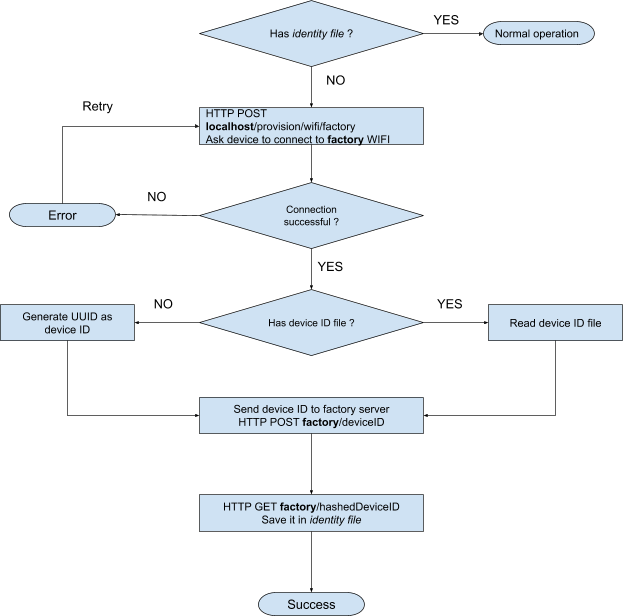
Manufacturers often add default configurations and SSL certificates in the factory where the device is built so it can be used out of the box. Since our devices connect to the internet we need at least a unique device ID so we can address this device. CloudREST daemon also has the ability to use client certificates for mutual server-client authentication but this is not checked on server. The daemon also has a procedure to perform in-factory provisioning for WIFI connected devices. Currently the procedure flow depends on the device REST service to control the WIFI and an external service, which usually is another server running in factory, to store the provisioned device ID. The REST service API is currently hardcoded in the daemon source.
In the flowchart above, the identity file is a normal file that resides in the same folder with the daemon. This file is created after the device ID is saved to factory server and sent back as device ID hashed with SHA256. The device ID file is a normal file (with path hardcoded in daemon sources) that contains the device ID.
This device ID can be read directly from a piece of hardware and as most embedded devices come with NAND or NOR Flash memory as storage they usually include a unique serial number that can be used as device ID. As an example the Winbond Flash memory provides a special instruction to read this ID (in this case over SPI):[146]
Usually, Linux kernels don’t offer a way to retrieve this number (since it is manufacturer specific) but support it’s easy to add on most kernel versions[147] and the output is shown below:
cat /sys/class/spi_master/spi0/spi0.0/machine_udid
D36270489F0A3821
The /sys/class/spi_master/spi0/spi0.0/machine_udid is the device ID file after communicating with factory server the identity file will contain a hashed device ID:
02acdd855df7bd8dd21ee5c8fe8462a498bdfc85488c79f60309a48f646a959f
We overview the steps that a client application must perform to use the RESTful API on the device. Since we built a solution that is accessible both locally and from internet there are a few differences that we must highlight.
For local network:
For internet access:
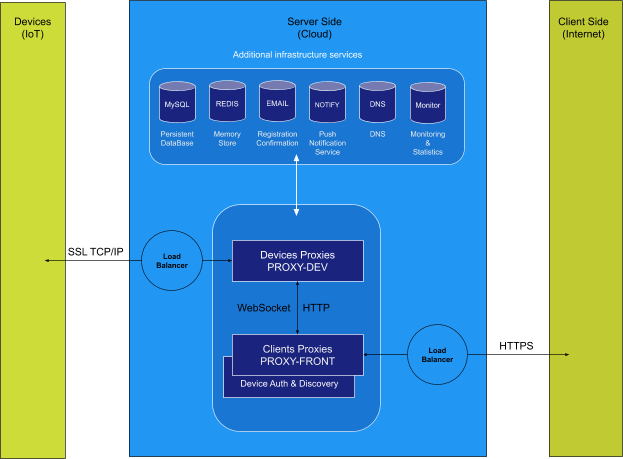
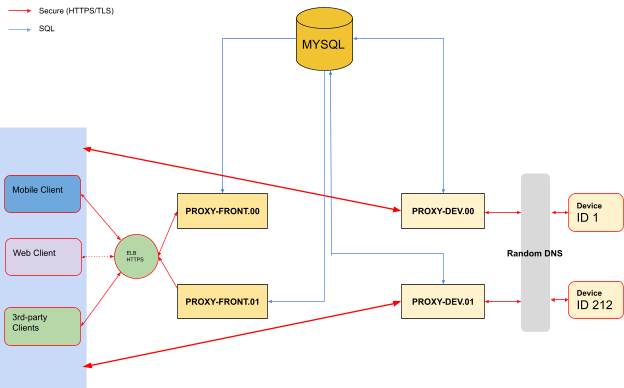
On the server side is where clients (browsers, mobile and 3rd party web services) and devices meet. These are the two big parts that separate the duties of the architecture. A third part is additional services that we need either the correlate the two principal parts or to provide additional services. We intend to have a horizontally scalable architecture for all three parts: devices, clients and additional services.
The part where the clients connects is going to be called either Clients Proxies or PROXY-FRONT in diagrams. The second part where devices will be connecting will be called either Devices Proxies or PROXY-DEV in diagrams.
For connections, we use round-robin for TCP/IP and least outstanding requests for HTTPS load balancing[148] to direct traffic to the instances of PROXY-DEV or PROXY-FRONT. Also, load balancers are used to offload SSL[149] traffic from the two proxies.
We use the term proxy to better reflect that both PROXY-DEV or PROXY-FRONT are actually intermediaries for actual device or client destinations.
A quick overview of the duties and operation of the PROXY-FRONT and PROXY-DEV would be:
Both PROXY-FRONT and PROXY-DEV are written in NodeJS[150] and use several libraries:
For the additional services we use:
For demo purposes, we also use a small, unscalable implementation written in Python.
Although the services that we use are pretty much vendor independent, we deployed our architecture on Amazon AWS services:
The architecture that we are proposing is designed to scale horizontally by automatically increasing or decreasing the number of instances depending on necessities.
Considering that our implementation uses NodeJS which which is a single threaded process with standard maximum memory usage of 1 GB our instances can have this minimum configuration. This corresponds to a t2.small EC2 instance on AWS which also allows burstable network performance[158].
Usually, when deploying CloudREST code to an Linux virtual or real machine, some tuning might be necessary to achieve the best performance[159]. Our server instance uses a single port to accept any number of clients but this uses a different socket descriptor for each accepted connection. To increase the maximum number of socket descriptors available the number of maximum open files must be increased.
First the kernel maximum fs.nr_open must be increased:
echo 10000000 > /proc/sys/fs/nr_open
Then, the user process limits can be increased using the ulimit command:
ulimit -n 10000000
The process of binding one or more devices to an email address takes place on device. The email address is set when user first setup the device using the manufacturer provided application. As mentioned on “Device Side - Connecting our device“ paragraph the CloudREST daemon will perform a REST API call on http://localhost/device to obtain this email address when daemon starts.
This email address is sent to the cloud server and save it in the MySQL database as an address for the corresponding Device ID with the attribute “confirmed” set to false. The server will have to send an email to the unconfirmed email address with a link that user should click to confirm this email address. The generated confirmation link is handled by the REST API on the PROXY-FRONT.
For the user authentication the email address setup on device is used. Depending if CloudREST daemon requires or not authentication to use the manufacturer device REST API there are two ways the authentication can implemented:
To facilitate device discovery, authentication and email confirmation the service exposes a REST API on PROXY-FRONT servers. All REST API calls should be done to a hostname that points to PROXY-FRONT load balancer (ie: https://myservice.domain/<api call>).
POST /v1/auth
Requires access token: NO
Request Body:
{
“email”: “email address”,
“password: “password”,
“remember”: true
}
Response Success:
{
“access_token”: “access token”,
“expires”: “expiration date ISO9660 format”,
“devices” : [
{
“id”: “device id”,
“name”: “device name”,
“online”: true
}
]
}
Response Fail:
{
“error”: 401,
“message”: "Unauthorized"
}
GET /v1/devices/list
Requires access token: YES
Response Success:
{
“devices” : [
{
“id”: “device id”,
“name”: “device name”,
“online”: true
}
]
}
GET /v1/confirmation?confirmationId=”uuid”
Response Success/Fail: Will redirect to a web page
Requires access token: NO
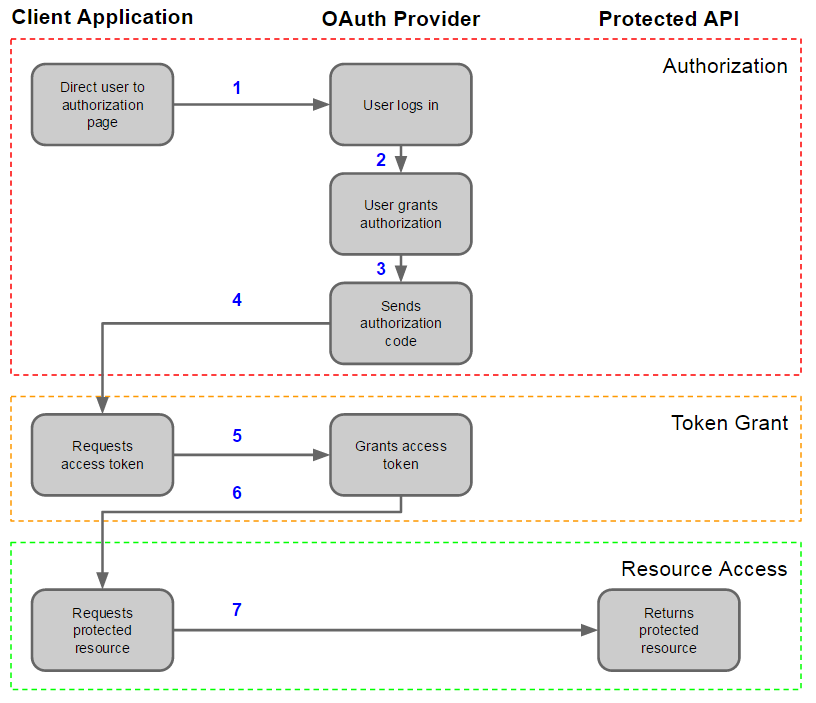
For integrations with other web services the PROXY-FRONT provides a basic OAuth[160] API. The process flow is summarized in the image below (taken from [161]):
The CloudREST oAuth REST API:
POST /v1/oauth/authorize - OAuth authorize
POST /v1/oauth/authorize/validate - OAuth validate
POST /v1/oauth//token - OAuth access token
POST /v1/oauth//token/validate - OAuth access token validation
First implementation used a DNS round-robin load balancing. A file containing several server hostnames was available for CloudREST daemon to read. Each of these hostnames resolved to one or more IP addresses. The CloudREST daemon will resolve the hostnames, build a list of IP addresses and use Fisher-Yates random shuffle[162] to obtain an IP address. Once IP was obtained the connection was initiated and in case of connection failure another IP was randomly taken from the list and process repeated.
The problem with this approach is that it requires more server instances than necessary each instance with several IP. Beside that it can’t make any assumption about the number of devices already connected to the server instance that it tries to connect or the load on that instance. In our initial tests we were using two server instances with 3 IP assigned to each and 10.000 devices.
The first implementation architecture was composed from:
The PROXY-FRONT instances were behind a load balancer (Amazon AWS ELB[163]), on which a RESTful API was implemented so that clients can query what devices belonging to the user and obtain the IP address of PROXY-DEV server that they need to connect to communicate with the device. The response of this query was a list of devices:
{
"devices": [
{
"deviceId": "4u5am0b",
"mac": "18:C8:E7:81:9E:7B",
"deviceUrl": "56.176.12.176",
"name": "My Device Name"
}
]
}
Using this information the clients could build the device REST API URL and start issuing REST API calls to devices.
A secondary function was added to PROXY-FRONT instance especially for browser and other 3rd party web applications. To hide the actual IP address of the PROXY-DEV instance from the web applications, a special HTTP routing table was added which would transparently forward requests done on PROXY-FRONT instance to the proper PROXY-DEV instance.
Internally, the PROXY-FRONT instances were querying the MySQL server to find the mapping between the device ID and the PROXY-DEV instance.
The PROXY-DEV instances were accepting connection on two endpoints, one from the clients (or PROXY-FRONT instances) and another from devices. When a device was connecting to an instance the PROXY-DEV would update the mapping between its IP and device ID into the MySQL server. When a client was sending a request the PROXY-DEV would lookup internally the socket on which the device was connected and send the request to it. When response came back from device it would forward back to clients.
One of the first issues was that the PROXY-DEV instances were processing encrypted HTTPS traffic on both endpoints. This causes a lot of load on the instances. This could be solved by using a load balancer to offload the encryption and only deal with lighter non-encrypted traffic.
Another issue was that the PROXY-DEV instances were processing both clients and devices, with each new client opening a new socket on the same PROXY-DEV to which the device was connected. With asynchronous applications and other 3rd party services it was common that client connections were 5 times more than device connections, but there was no way to scale the the PROXY-DEV based on client connections.
Beside sending data from clients to devices, the PROXY-DEV also had to handle the device initial TCP/IP connect and update the MySQL database with the connected or disconnected devices. Since all our connected devices were wireless, weak wireless signal was causing frequent disconnects and reconnects. While reconnecting the device could migrate to the second instance but clients would still be connected to first instance.
With many concurrent updates and queries MySQL was becoming a point of bottleneck especially during device reconnects or during peak hours when many clients were trying to access device.
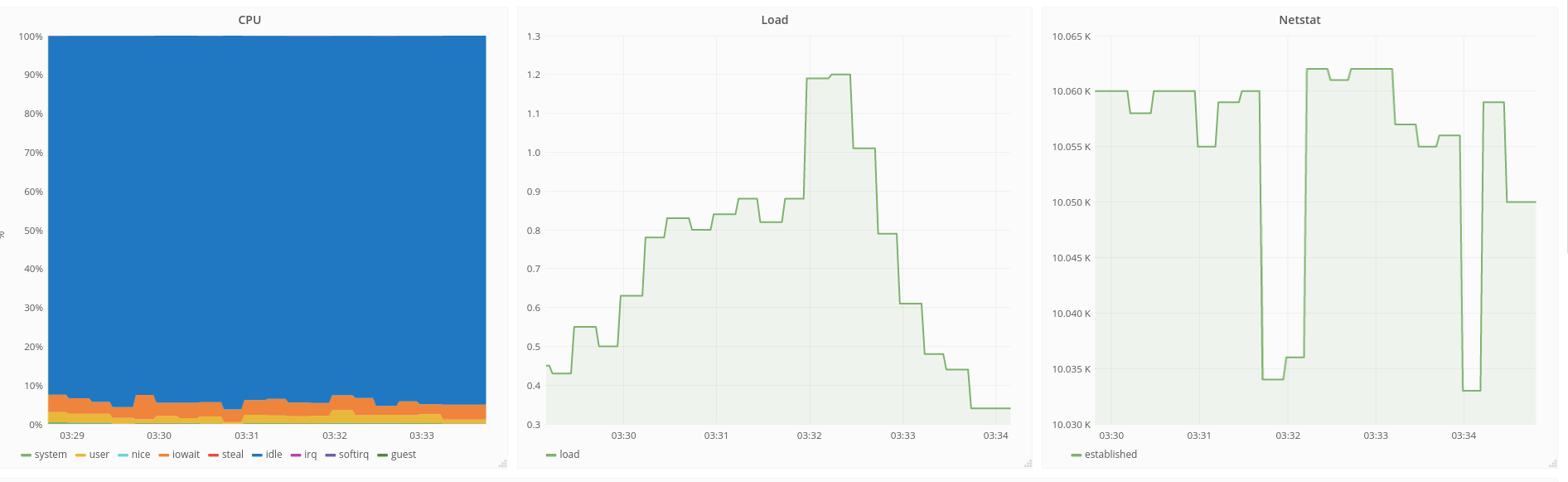
Below we are showing some situations using real live data for around 10.000 devices connected. All screenshots are from Amazon AWS CloudWatch monitoring service.
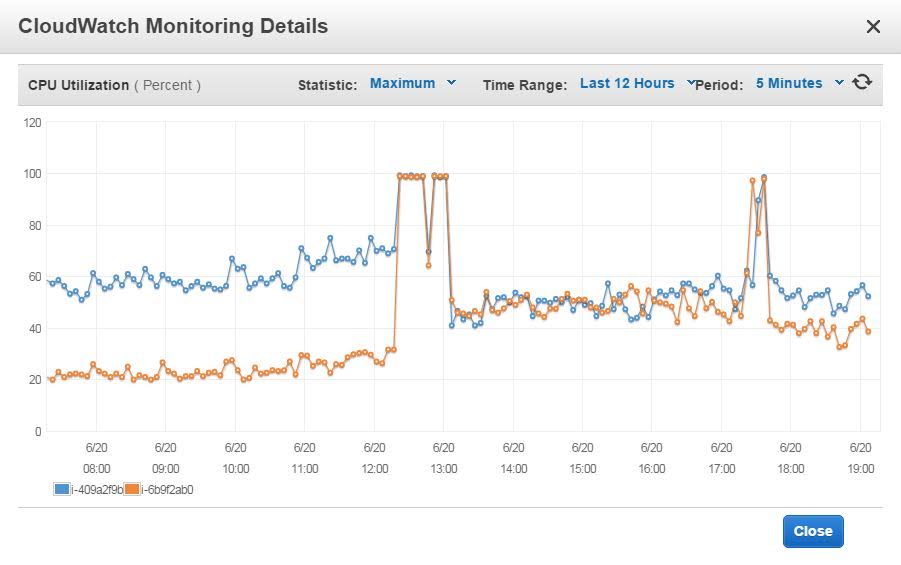
In the screenshot above, the blue and orange lines represent the CPU utilization of the two running instances of PROXY-DEV. The blue instance had a much bigger CPU utilization as it had much more devices connected than the orange instance. As more and more traffic was inbound the blue instance reached 100% CPU and the clients or devices connected were starting to timeout and be dropped. This also leads to disconnects to already connected devices. So there was a large bulk of devices disconnected that tried to reconnect all at once (or at a small interval). Since the blue instance was no longer responded, most of the reconnects were going to orange instance resulting the orange instance going 100% CPU also and timing out devices. In the end, some balancing was achieved but the service was down or intermittently accessible for nearly 5 hours.
This particular case was showing the limits of balancing connection using a random pick of server.
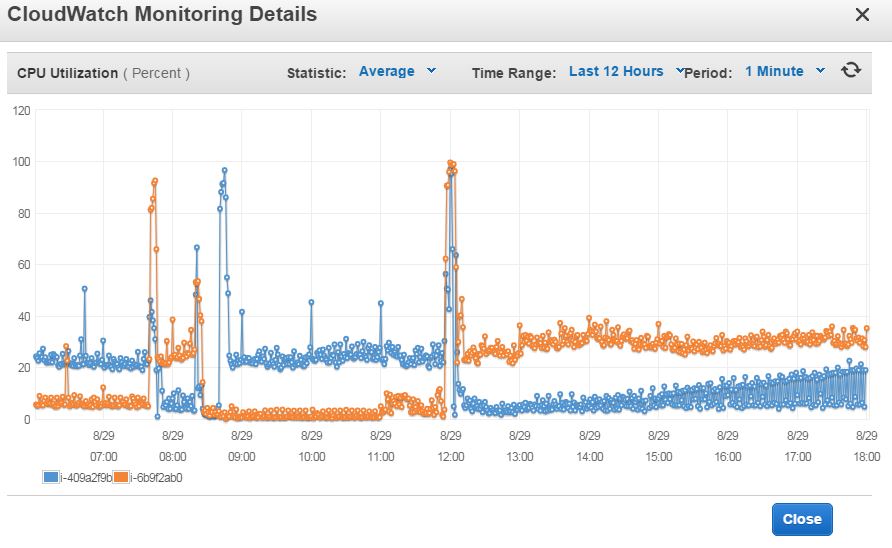
Another example involved several instance crashes during client load, happening in the morning when most people will check different statuses of devices. As visible in the screenshot above the blue instance had gone from 30% CPU load to 0% in a small timeframe while the orange one took the hit from many incoming client connections reaching 100% CPU then dropped to 0% CPU. Both clients and devices were in a ping-ponged between instances several times and during this time the clients couldn’t access the devices smoothly.
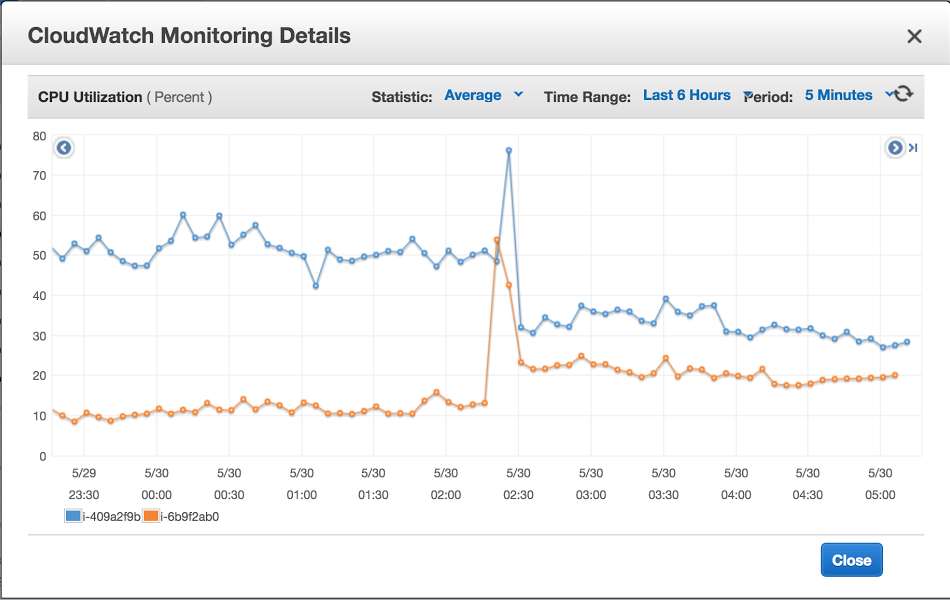
Above we have another example, with both PROXY-DEV instances reaching 100% CPU almost simultaneously resulting in service downtime.
From these issues, several conclusions were reached:
Using the conclusions that we reached in previous chapter we changed the architecture as follows:
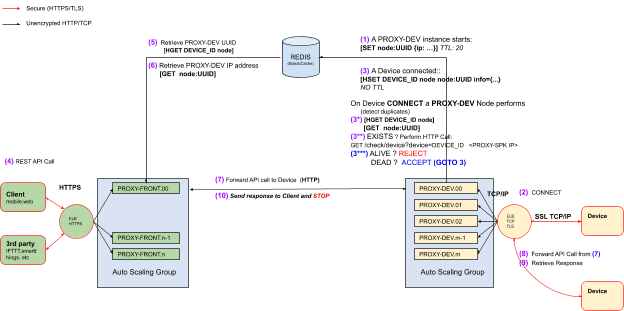
The actual flow from client to device and back is presented in the diagram above including the REDIS commands that are used for inter-instance communication.
The REDIS keys that we use are:
<device id>:node:<UUID> with the value a hash with device information. This key never expires, but is overwritten when a device connects.
In this diagram REDIS is the “single point of failure” and the question is how we will handle the situation when REDIS has crashed or has been restarted.
The most simplistic approach would be to disconnect all devices from all PROXY-DEV instances. This has the advantage as it won’t need any extra code to handle. The node:<UUID> will be refreshed automatically by running PROXY-DEV instances and the <device id>:node:<UUID> key will be set when devices will reconnect.
Another approach is for every PROXY-DEV to loop over the list of its connected devices sockets and set the corresponding keys again but it wasn’t implemented in our first tests.
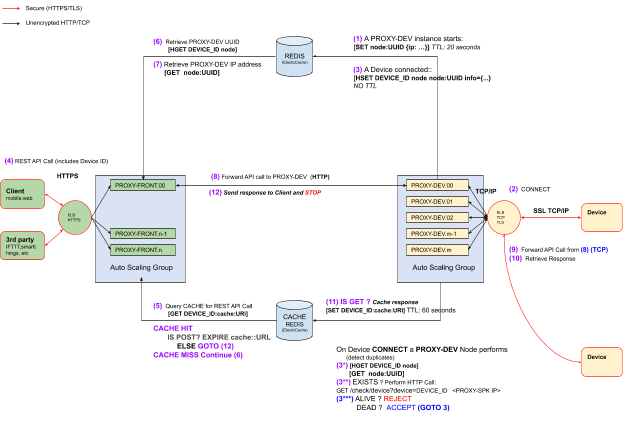
We still have not addressed two of the HTTP/1.1 disadvantages:
The main bottleneck when clients repeatedly poll for resources is between the PROXY-DEV instances and the device, where a single TCP/IP connection is available this can be greatly improved by implementing a caching mechanism. To solve it at client level we need to use one of the HTTP features that we presented in Communication Protocols chapter like Server Sent Events.
The second issue, of the multiple short lived connections can be mitigated by reusing already opened connections to reduce the latency resulted from the time spend on a new connection handshake. With HTTP/1.1 the mechanism is called persistent connections [164] [165] and it is setup by sending a special header: Connection: keep-alive. For clients that connect to PROXY-FRONT this depends on how client is written, but should be default behaviour for HTTP/1.1 communications. As an example browsers open multiple connections per host with keep-alive header set for connection reuse, but we can not make the same assertion for the other clients’ implementations.
We can control this behavior between PROXY-FRONT and PROXY-DEV by instructing the http-proxy NodeJS module that we use to create a keep alive agent for each PROXY-DEV destination with a certain pool of sockets[166]. However persistent HTTP/1.1 connections suffer from “head of line” blocking[167] on each request must wait for its response before next request can be sent in a synchronous operation. To improve this we need a protocol that can asynchronously process multiple requests and responses in HTTP/2 this is called multiplexing.
At client level, between clients and PROXY-FRONT, it means replacing HTTP/1.1 with a protocol like WebSocket or HTTP/2. On current architecture, we don’t try to solve at this level as it would mean to reduce compatibility of architecture while not having a big performance improvement since the load balancers could handle easily the multiple connections. But we can try to minimize the connections between PROXY-FRONT and PROXY-DEV by using a limited number of bidirectional multiplexing connections between them, and using these pre-configured connections in a round robin fashion. This means that we will be creating a connection pool of certain size between each PROXY-FRONT and PROXY-DEV. This will reduce the number of possible sockets opened on both instances types and waive the cost of setting up a new connection everytime a request or response is in flight.
Caching is effective when multiple clients request the same REST resource or when they request the same resource periodically while the resource doesn’t change. RESTful APIs differentiate easily when a resource is retrieved or changed. The GET HTTP method means retrieval and we will be caching the response and POST/PUT/PATCH methods means a resource has been modified and we will invalidate the cache for that resource URI.
Device REST API developers can implement a more advanced caching of resources by using HTTP headers. This has the benefit to reduce polling done by clients. Since this is mostly dependant on how REST API developers implement the API we only mention this lightly, as a more comprehensive documentation to consider is RFC 2616[168]:
Detecting changes: For all resources server adds Last-Modified field on response header. Clients should save this value and use it on further calls to the resource with If-Modified-Since set to last know Last-Modified value for this resource on header. The server will reply with 304 - Unmodified if no modifications happen since If-Modified-Since timestamp.
Concurrent changes: When using PUT or PATCH on a resource add If-Modified-Since on request headers which should have the value of the Last-Modified from the last GET on that resource. If resource is newer than known server will reply with 412 Pre-Condition Failed [169]
For our architecture we described how caching works in the introductory paragraph for this chapter. We will only present how we are implementing this using REDIS using SET and GET commands that are used to set or get a value from a key. This operations are fast with a time complexity of O(1). The caching algorithm can be summarized as:
Example:
127.0.0.1:6379> set 67abASP4:cache:/watering/log/2016-01-01/30/zone/1 '{"data": "response"}'
(integer) 1
127.0.0.1:6379> get 67abASP4:cache:/watering/log/2016-01-01/30/zone/1
"{\"data\": \"response\"}"
When using REDIS as a cache, it’s important to configure maxmemory and maxmemory-policy parameters. This way REDIS can be used as a Least-Recently Used (LRU) cache automatically (allkeys-lru) expiring least accessed key or to take hints from the keys TTL with the volatile-ttl setting. In our setup we use the former.
The keys are set with a TTL because REST API resources can be modified by calls sent through local network. To expire those CloudREST daemon needs to act as a local HTTP server and all calls local network to go through it. At the time of this paper this feature was not implemented.
To send the notifications received through the CloudREST named pipe/socket to clients we use Server Sent Events, a protocol standardised by World Wide Web Consortium, with good browser and programming languages support. We must note that all browsers except Microsoft Edge browser support this protocol. For Microsoft Edge the support for Server Sent Events is under consideration[170]. To implement the notification system with SSE we will going to use the CHANNEL PUBLISH/SUBSCRIBE feature of REDIS. This will allow the PROXY-FRONT instances to use REDIS SUBSCRIBE command on a DEVICE_NOTIFICATION channel on which PROXY-DEV publishes data received from devices as notification. With the PUBLISH/SUBSCRIBE pattern the PROXY-FRONT instances don’t have to poll periodically for new data. The process is summarized in the diagram below:
To reduce the number of connections opened between PROXY-FRONT and PROXY-DEV we replace the simple HTTP/1.1 protocol forwarding with a bidirectional multiplexing protocol like WebSocket or HTTP/2. While HTTP/2 solves many issues like automatic correct request/response binding, multiplexing, data serialization, and server push notifications was not mature enough at the date this research was conducted so we choose to use WebSocket[171] protocol with the possibility to change to HTTP/2 in the future.
With WebSocket we can send requests without waiting for previous request response but we need to tag each request/response pair with an unique ID (uuid) so we can send the proper response to the client request, a feature that is built in HTTP/2. We solve this by adding a custom header to HTTP request when received by PROXY-FRONT that contains an uuid: x-cloudrest-id: <uuid>. It’s important that the REST service on device send back this header unmodified. Once PROXY-FRONT receives a response with this header it can send the response back to client.
Beside request/response mapping we also need to serialize the HTTP protocol in a WebSocket message. For this, we use the same simple serialization that we use for PROXY-DEV to DEVICE messages mentioned in Chapter 2 - Device Side - Connecting our device.
Once the message has been built it can be send over the websocket connection. The process is exemplified in the diagram below:
To improve performance there should be more than a single WebSocket connection opened between each PROXY-FRONT and each PROXY-DEV. A pool of multiple but fixed websocket connections used in a round robin manner can improve performance.
The last topic that we address for improving the architecture is to reduce the number of REDIS queries when clients connect to PROXY-FRONT. For each new client connection there are two REDIS queries that needs to be execute. Although this queries execute very fast it might become an issue when number of clients is of millions order. To reduce the queries we cache the mapping between Device ID and PROXY-DEV IP to which is connected locally, on all PROXY-FRONT instances. To reduce the memory for this local caching we employ two structures:
So every time a new client connect we first look into this Device_ID map and get the IP to which the connection must be forwarded. If not found we simply query the REDIS and put the information obtained in the two maps.
This cache needs to be expired when devices connect or disconnect or when PROXY_DEV instances are destroyed/created. Similarly to the method employed for device notifications we make all PROXY-FRONT instances SUBSCRIBE to a DEVICE:CHANGES channel on REDIS. When PROXY-DEV has a client connect or disconnect, we PUBLISH a message to this channel which will be received by all PROXY-FRONT instances and the cache will be deleted.
The final architecture diagram presented below includes the improvements mentioned:
Our principal aim was to solve the initial architecture biggest issues which were mostly related to performance and crashes during high load. From our internal conducted tests, these issues were solved. To compare the performance of the two architectures is more difficult. Although we were able to simulate the same REST API calls by deploying several virtual machines with the CloudREST daemon and the REST API build in Python this is quite different than actual devices.
Another difference that made performance comparison difficult was that on initial architecture clients could connect directly to the PROXY-DEV instance. This would theoretically provide better performance since there were less “hops” for a message.
Considering this we believe that the new architecture will perform better because:
The biggest gains would come from implementing the proposed improvements presented in “Improving the architecture” chapter. On our tests sending a 4k message between two entities using HTTP and WebSocket, had around 4x improvement when using WebSocket version, from ~900ms for HTTP to 230ms on WebSocket version.
The caching should improve the performance, the initial architecture had a massive problem with repeatedly polling the device REST API. This led to some caching approaches implemented in clients but they were not uniformly implemented across all clients.
We believe that the improved architecture would perform very well under high load while providing good performance. As the HTTP/2 support and implementations will become ubiquitous the architecture will permit the adoption of HTTP/2 protocol in the future. This should result in more performance especially on CLIENT to PROXY-FRONT level where we preferred compatibility instead of forcing clients to use another protocol like WebSocket.
As one of our principal motivations (Open the Black Box) for this thesis, we presented the internals of an architecture for interconnecting IoT devices. We presented all aspects involved in the process of connecting a device with internet and other web services, including the factory provisioning process.
Not “Internet only” was another of the objectives of this paper which we presented a solution. It’s important for devices to still offer local or direct access although internet is ubiquitous on most parts of the works, there are still situations and cases where a direct access is prefered.
By using only the standard HTTP protocol and its extensions for client connectivity we have promoted interoperability of our architecture and the rest of the web. Although the architecture is not limited to only using a RESTful API, most of the research and implementation is focused on promoting RESTful services.
Our, on device, CloudREST daemon can be used independently from the main software that runs on devices allowing developers to focus on implementing their own software instead of dealing various vendor specific vagaries of their services SDK. Using standard libraries widely available on diverse hardware architectures and OS flavors we attained the objective to not require a special SDK.
The architecture presented uses only open-source solutions/software so device manufacturers and developers are not locked in any vendor specific environment. All objectives from the motivations had been reached, and the architecture has future upgradability with the advent of the HTTP/2 standard adoption.
[1] Simon Duquennoy ,Gilles Grimaud, Jean-Jacques Vandewalle: Smews: Smart and Mobile Embedded Web Server, Complex, Intelligent and Software Intensive Systems, 2009. CISIS '09. International Conference on
[2] Li Xian-Hui, Liu Jing-Biao, Cai Wen-Yu: Design and Implementation of Web Server Control System Based on STM32, Intelligent Networks and Intelligent Systems (ICINIS), 2012 Fifth International Conference on
[3] Vasileios Karagiannis, Periklis Chatzimisios, Francisco Vazquez-Gallego, Jesus Alonso-Zarate: A Survey on Application Layer Protocols for the Internet of Things, Transaction on IoT and Cloud Computing, 2015.
[4] Sven Bendel, Thomas Springer, Daniel Schuster, Alexander Schill, Ralf Ackermann, Michael Ameling: A Service Infrastructure for the Internet of Things based on XMPP. Pervasive Computing and Communications Workshops (PERCOM Workshops), 2013 IEEE International Conference on
[5] Adrian Hornsby, Eloi Bail: μXMPP: Lightweight implementation for low power operating system Contiki, Ultra Modern Telecommunications & Workshops, 2009. ICUMT '09. International Conference on
[6] Raphael Cohn: A Comparison of AMQP and MQTT, stormmq.com 2011
[7] Jorge E. Luzuriaga, Miguel Perez, Pablo Boronat, Juan Carlos Cano, Carlos Calafate, Pietro Manzoni: A comparative evaluation of AMQP and MQTT protocols over unstable and mobile networks, Consumer Communications and Networking Conference (CCNC), 2015 12th Annual IEEE
[8] Dinesh Thangavel, Xiaoping Ma, Alvin Valera, Hwee-Xian Tan, Colin Keng-Yan Tan: Performance evaluation of MQTT and CoAP via a common middleware
[9] Markku Laine, Kalle Säilä: Performance Evaluation of XMPP on the Web, Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), 2014 IEEE Ninth International Conference on
[10] Joel L. Fernandes, Ivo C. Lopes, Joel J. P. C. Rodrigues, and Sana Ullah: Performance Evaluation of RESTful Web Services and AMQP Protocol, Conference: Ubiquitous and Future Networks (ICUFN), 2013 Fifth International Conference on
[11] ZB Babovic, J Protic, V Milutinovic: Web Performance Evaluation for Internet of Things Applications, IEEE Access 4, 6974-6992 2016
[12] Richard Mietz, Sven Groppe, Kay Römer and Dennis Pfisterer: Semantic Models for Scalable Search in the Internet of Things, Journal of Sensors and Actuator Networks 2013, 2(2), 172-195
[13] Dominique Guinard: A Web of Things Application Architecture - Integrating the Real-World into the Web ETH Zurich 2011
[14] L. Atzori, A. Iera, and G. Morabito: ‘‘The Internet of Things: A survey,’’ , Computer Networks: The International Journal of Computer and Telecommunications Networking, Volume 54 Issue 15, October, 2010
[15] A. Al-Fuqaha, M. Guizani, M. Mohammadi, M. Aledhari, and M. Ayyash:‘‘Internet of Things: A survey on enabling technologies, protocols, and applications’’ IEEE Communications Surveys & Tutorials Volume: 17, Issue: 4, Fourthquarter 2015
[16] K. Ma and R. Sun, ‘‘Introducing WebSocket-based real-time monitoring system for remote intelligent buildings’’ International Journal of Distributed Sensor Networks, 2013
[1] "Can't sign in to Google calendar on my Samsung refrigerator ...." 19 Nov. 2014, http://productforums.google.com/d/topic/calendar/UhfpcwO0X0c.
[2] "Hack Brief: Yahoo Breach Hits Half a Billion Users | WIRED." https://www.wired.com/2016/09/hack-brief-yahoo-looks-set-confirm-big-old-data-breach/.
[3] "Dropbox hack leads to leaking of 68m user passwords on the internet ...." 31 Aug. 2016, https://www.theguardian.com/technology/2016/aug/31/dropbox-hack-passwords-68m-data-breach.
[4] "117 million LinkedIn emails and passwords from a 2012 hack just got ...." 18 May. 2016, https://techcrunch.com/2016/05/18/117-million-linkedin-emails-and-passwords-from-a-2012-hack-just-got-posted-online/.
[5] "5 million Gmail passwords leaked - Sep. 10, 2014 - CNN Money." 10 Sep. 2014, http://money.cnn.com/2014/09/10/technology/security/gmail-hack/index.html.
[6] "RFC 7228 - Terminology for Constrained-Node Networks - IETF Tools." https://tools.ietf.org/html/rfc7228.
[7] "iot.eclipse.org — Working Group." https://iot.eclipse.org/working-group/.
[8] "IEEE Internet of Things: Home." http://iot.ieee.org/.
[9] "AGILE IoT Community website – Adaptive Gateways for dIverse ...." http://agile-iot.eu/.
[10] "the internet of things | IoT council, a thinktank for the Internet of Things." http://www.theinternetofthings.eu/.
[11] "Smews: Smart and Mobile Embedded Web Server - IEEE Xplore ...." http://ieeexplore.ieee.org/document/5066843.
[12] "Miniweb - TCP/IP stack and web server in 30 bytes." http://dunkels.com/adam/miniweb/.
[13] "Design and Implementation of Web Server Control System Based on ...." http://ieeexplore.ieee.org/document/6376506/.
[14] "What is ZigBee? | zigbee alliance." http://www.zigbee.org/what-is-zigbee/.
[15] "Z-Wave the Smartest Choice for your Smart Home." http://www.z-wave.com/.
[16] "dev-esp32 - NodeMCU Documentation - Read the Docs." https://nodemcu.readthedocs.io/en/dev-esp32/.
[17] "GitHub - micropython/micropython-esp32: MicroPython ported to the ...." https://github.com/micropython/micropython-esp32.
[18] "ESP32 Overview | Espressif Systems." https://www.espressif.com/en/products/hardware/esp32/overview.
[19] "LinkIt Smart 7688 - Seeed Wiki - Seeed Studio." 20 Jul. 2016, http://wiki.seeedstudio.com/wiki/LinkIt_Smart_7688.
[20] "MediaTek MT7688 Datasheet - MediaTek Labs." https://labs.mediatek.com/en/download/50WkbgbH
[21] "Fact Sheet: Intel® Joule™ Platform - Intel Newsroom." 16 Aug. 2016, https://newsroom.intel.com/newsroom/wp-content/uploads/sites/11/2016/08/intel-joule-fact-sheet.pdf.
[22] "Nest Learning Thermostat technical specifications." 22 Feb. 2017, https://nest.com/ca/support/article/Nest-Learning-Thermostat-technical-specifications.
[23] "The Architecture of the Nest API | Nest Developers." 19 Apr. 2017, https://developers.nest.com/documentation/cloud/architecture-overview.
[24] "Works with Nest Store." https://workswith.nest.com/.
[25] "Direct, non-cloud API? - Tools and SDK's - Nest Developer Community." 20 Oct. 2016, https://nestdevelopers.io/t/direct-non-cloud-api/170.
[26] "Firebase - Google." https://firebase.google.com/.
[27] "Wink API · Apiary." http://docs.winkapiv2.apiary.io/.
[28] "Local Control Now Available for Wink-Compatible Lighting ... - Wink Blog." http://blog.wink.com/wink-blog/2016/2/10/local-control-now-available-for-wink-compatible-lighting-products.
[29] "[Discussion] Native Local Control via API with Wink Hub 2.49 - Reddit." 8 Feb. 2016, https://www.reddit.com/r/winkhub/comments/44p4x5/discussion_native_local_control_via_api_with_wink/.
[30] "Universal Plug and Play - Wikipedia." https://en.wikipedia.org/wiki/Universal_Plug_and_Play.
[31] "Ouimeaux: Open Source WeMo Control — ouimeaux 0.7.2 ...." https://ouimeaux.readthedocs.io/.
[32] "RainMachine · Apiary." http://docs.rainmachine.apiary.io/.
[33] "IFTTT.com." https://ifttt.com/.
[34] "Amazon SNS — Pub/Sub Messaging and ...." https://aws.amazon.com/sns/.
[35] "MQTT." http://mqtt.org/.
[36] Dinesh Thangavel, Xiaoping Ma, Alvin Valera: "Performance evaluation of MQTT and CoAP via a common middleware." http://ieeexplore.ieee.org/abstract/document/6827678/.
[37] "MQTT Programming In Depth - Programming with Reason." http://programmingwithreason.com/article-mqtt-in-depth.html.
[38] "STOMP." https://stomp.github.io/.
[39] "1.2 - Stomp." https://stomp.github.io/stomp-specification-1.2.html.
[40] "Architectural Styles and the Design of Network-based Software ...." https://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm.
[41] "Chunked transfer encoding - Wikipedia." https://en.wikipedia.org/wiki/Chunked_transfer_encoding.
[42] "Cross-document messaging - HTML Standard - WhatWG." https://html.spec.whatwg.org/multipage/comms.html.
[43] "What is HATEOAS and why is it important? - The RESTful cookbook." http://restcookbook.com/Basics/hateoas/.
[44] "HTTP/2." https://http2.github.io/.
[45] "HTTP: HTTP/2 - High Performance Browser Networking (O'Reilly)." https://hpbn.co/http2/.
[46] "HTTP: HTTP/2 - High Performance Browser Networking (O'Reilly)." https://hpbn.co/http2/.
[47] "RFC 7540 - Hypertext Transfer Protocol Version 2 (HTTP/2) - IETF Tools." https://tools.ietf.org/html/rfc7540#page-34.
[48] "What's new in HTTP 2 [LWN.net]." 10 Jul. 2013, https://lwn.net/Articles/558302/
[49] "Hypertext Transfer Protocol Version 2 (HTTP/2) - Specifications." 30 May. 2015, http://http2.github.io/http2-spec/#TLSUsage.
[50] "RFC 6066 - Transport Layer Security (TLS) Extensions ... - IETF Tools." https://tools.ietf.org/html/rfc6066.
[51] "HTTP/2 Frequently Asked Questions - Specifications." https://http2.github.io/faq/#does-http2-require-encryption.
[52] "RFC 7641 - Observing Resources in the Constrained ... - IETF Tools." https://tools.ietf.org/html/draft-ietf-core-observe-08.
[53] "Experimental Evaluation of Unicast and Multicast CoAP ... - NCBI - NIH." 21 Jul. 2016, https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4970179/.
[54] "RFC 7252 - The Constrained Application Protocol (CoAP) - IETF Tools." https://tools.ietf.org/html/rfc7252#section-4.
[55] "RFC 7252 - The Constrained Application Protocol (CoAP) - IETF Tools." https://tools.ietf.org/html/rfc7252#section-4.6.
[56] "draft-ietf-core-block-21 - Block-Wise Transfers in the ... - IETF Tools." 8 Jul. 2016, https://tools.ietf.org/html/draft-ietf-core-block.
[57] "RFC 6347 - Datagram Transport Layer Security Version 1.2 - IETF Tools." https://tools.ietf.org/html/rfc6347.
[58] "RFC 6455 - The WebSocket Protocol - IETF Tools." https://tools.ietf.org/html/rfc6455.
[59] "HTTP/1.1 Upgrade header - Wikipedia." https://en.wikipedia.org/wiki/HTTP/1.1_Upgrade_header.
[60] "RFC 6455 - The WebSocket Protocol - IETF Tools." https://tools.ietf.org/html/rfc6455.
[61] "RFC 6455 - The WebSocket Protocol - IETF Tools." https://tools.ietf.org/html/rfc6455#section-5.6.
[62] "WebSocket - Wikipedia." https://en.wikipedia.org/wiki/WebSocket.
[63] "GitHub - jeremyhahn/cwebsocket: High performance websocket client ...." https://github.com/jeremyhahn/cwebsocket.
[64] "libwebsockets." https://libwebsockets.org/.
[65] "libwebsockets/README.esp32.md at master · warmcat/libwebsockets ...." 31 Mar. 2017, https://github.com/warmcat/libwebsockets/blob/master/README.esp32.md.
[66] "MQTT Websocket Client - HiveMQ." http://www.hivemq.com/demos/websocket-client/.
[67] "Advanced Message Queuing Protocol (AMQP) WebSocket Binding ...." http://docs.oasis-open.org/amqp-bindmap/amqp-wsb/v1.0/amqp-wsb-v1.0.html. 2017.
[68] "STOMP Over WebSocket - Jeff Mesnil." http://jmesnil.net/stomp-websocket/doc/.
[69] "Connecting Your DDS Apps to Web Services using Javascript and ...." 14 Jan. 2015, https://blogs.rti.com/2015/01/14/connecting-your-dds-apps-to-web-services-using-javascript-and-node-js/.
[70] "AMQP is the Internet Protocol for Business Messaging | AMQP." https://www.amqp.org/about/what.
[71] "A Survey on Application Layer Protocols for the Internet of Things." https://pdfs.semanticscholar.org/ca6c/da8049b037a4a05d27d5be979767a5b802bd.pdf.
[72] "What is DDS? - Object Management Group Portals." http://portals.omg.org/dds/what-is-dds-3/.
[73] "DDS: the Right Middleware for the Industrial Internet of Things?." https://info.rti.com/hubfs/whitepapers/Right_Middleware_for_IIoT.pdf.
[74] "TCP Transport for RTI Data Distribution Service - RTI Community." http://community.rti.com/docs/html/tcp_transport/main.html.
[75] "DDS - Object Management Group." http://www.omg.org/news/meetings/workshops/RT-2007/00-T5_Hunt-revised.pdf.
[76] "XMPP | An Overview of XMPP." https://xmpp.org/about/technology-overview.html.
[77] "A Service Infrastructure for the Internet of Things based on XMPP." 19 Mar. 2013, http://ai2-s2-pdfs.s3.amazonaws.com/6b74/b436564a9871cd34c2cd0f4d68c32d03906a.pdf.
[78] "μXMPP: Lightweight implementation for low power operating system ...." http://ieeexplore.ieee.org/abstract/document/5345594/.
[79] "XMPPClient - Cookbook | mbed." https://developer.mbed.org/cookbook/XMPPClient.
[80] "XEP-xxxx: Quality of Service - XMPP." 12 Nov. 2015, https://xmpp.org/extensions/inbox//qos.html
[81] "XEP-0124: Bidirectional-streams Over Synchronous HTTP ... - XMPP." https://xmpp.org/extensions/xep-0124.html.
[82] "Internet of Things-Sensor Data." https://xmpp.org/extensions/xep-0323.html.
[83] "Internet of Things-Control." https://xmpp.org/extensions/xep-0325.html.
[84] "Internet of Things-Provisioning." https://xmpp.org/extensions/xep-0324.html.
[85] "XEP-0030: Service Discovery - XMPP." https://xmpp.org/extensions/xep-0030.html.
[86] "XEP-0203: Delayed Delivery - XMPP." 15 Sep. 2009, https://xmpp.org/extensions/xep-0203.html.
[87] (2015, April 7). IoT Developer Survey 2015 - SlideShare., from https://www.slideshare.net/IanSkerrett/iot-developer-survey-2015
[88] (2016, April 14). IoT Developer Survey - IEEE Internet of Things, from http://iot.ieee.org/images/files/pdf/iot-developer-survey-2016-report-final.pdf
[89] "IoT Developer Survey - IEEE Internet of Things." 14 Apr. 2016, https://ianskerrett.wordpress.com/2017/04/19/iot-developer-trends-2017-edition/.
[90] (n.d.). IFTTT.com. https://ifttt.com/
[91] "mqtt - npm." https://www.npmjs.com/package/mqtt.
[92] "GitHub - legastero/stanza.io: Modern XMPP in the browser, with a ...." https://stanza.io/.
[93] "GitHub - jmesnil/stomp-websocket: Stomp client for Web browsers and ...." https://github.com/jmesnil/stomp-websocket.
[94] "Copper (Cu) :: Add-ons for Firefox - Firefox Add-ons - Mozilla." 18 Dec. 2016, https://addons.mozilla.org/en-US/firefox/addon/copper-270430/.
[95] "Advanced Message Queuing Protocol (AMQP) WebSocket ... - Oasis." http://docs.oasis-open.org/amqp-bindmap/amqp-wsb/v1.0/cs01/amqp-wsb-v1.0-cs01.doc.
[96] "Kaazing.com - Kaazing WebSocket Gateway 5 Docs." https://kaazing.com/doc/5.0/websocket_client_docs/dev-js/o_dev_js.html.
[97] "GitHub - xinchen10/awesome-amqp: A curated list of AMQP 1.0 ...." https://github.com/xinchen10/awesome-amqp.
[98] "RTI Connext DDS Professional - Real-Time Innovations." https://www.rti.com/products/dds..
[99] "GitHub - rticommunity/rticonnextdds-connector: RTI Connector for ...." https://github.com/rticommunity/rticonnextdds-connector.
[100] "GitHub - ThomasBarth/WebSockets-on-the-ESP32: WebSocket ...." https://github.com/ThomasBarth/WebSockets-on-the-ESP32.
[101] "1248/microcoap - GitHub." https://github.com/1248/microcoap..
[102] "esp32-mqtt · GitHub." https://github.com/tuanpmt/esp32-mqtt/projects/1.
[103] "GitHub - Azure/azure-uamqp-c: AMQP library for C." https://github.com/Azure/azure-uamqp-c.
[104] "RTI Connext DDS Micro - Real-Time Innovations." https://www.rti.com/products/micro.
[105] "WhitePaper - A Comparison AMQP and MQTT." https://lists.oasis-open.org/archives/amqp/201202/msg00086/StormMQ_WhitePaper_-_A_Comparison_of_AMQP_and_MQTT.pdf.
[106] "A comparative evaluation of AMQP and MQTT - ResearchGate." https://www.researchgate.net/publication/282914203_A_comparative_evaluation_of_AMQP_and_MQTT_protocols_over_unstable_and_mobile_networks.
[107] "Performance evaluation of MQTT and CoAP via a common middleware." http://ieeexplore.ieee.org/document/6827678/.
[108] "Performance Evaluation of XMPP on the Web." 20 Apr. 2012, http://media.tkk.fi/webservices/personnel/markku_laine/performance_evaluation_of_xmpp_on_the_web.pdf.
[109] "Performance evaluation of RESTful web services and AMQP protocol ...." https://www.researchgate.net/publication/261235103_Performance_evaluation_of_RESTful_web_services_and_AMQP_protocol.
[110] "Web Performance Evaluation for Internet of Things Applications." 8 Nov. 2016, http://ieeexplore.ieee.org/iel7/6287639/7419931/07586113.pdf.
[111] "grpc / grpc.io." http://www.grpc.io/.
[112] "Extensible Markup Language (XML) - World Wide Web Consortium." https://www.w3.org/XML/.
[113] "JSON." http://www.json.org/.
[114] "Stop Comparing JSON and XML - Yegor256." 16 Nov. 2015, http://www.yegor256.com/2015/11/16/json-vs-xml.html.
[115] "RDF - Semantic Web Standards." https://www.w3.org/RDF/.
[116] "Semantic Models for Scalable Search in the ...." 27 Mar. 2013, http://www.mdpi.com/2224-2708/2/2/172.
[117] "A Web of Things Application Architecture - Integrating the Real-World ...." http://www.vs.inf.ethz.ch/publ/papers/dguinard-awebof-2011.pdf.
[118] "eishay/jvm-serializers Wiki - GitHub." https://github.com/eishay/jvm-serializers/wiki.
[119] "MessagePack: It's like JSON. but fast and small.." http://msgpack.org/index.html.
[120] "Protocol Buffers | Google Developers." https://developers.google.com/protocol-buffers/.
[121] "GitHub - google/flatbuffers: Memory Efficient Serialization Library." https://github.com/google/flatbuffers.
[122] "Apache Thrift - Home." https://thrift.apache.org/.
[123] "Welcome to Apache Avro!." https://avro.apache.org/.
[124] "Cap'n Proto." https://capnproto.org/.
[125] "eishay/jvm-serializers Wiki - GitHub." https://github.com/eishay/jvm-serializers/wiki.
[126] "RFC 2616 - Hypertext Transfer Protocol -- HTTP/1.1 - IETF Tools." https://tools.ietf.org/html/rfc2616#section-3.5.
[127] "AWS IoT SDKs - AWS Documentation." http://docs.aws.amazon.com/iot/latest/developerguide/iot-sdks.html.
[128] "Cloud IoT Core | Google Cloud Platform." https://cloud.google.com/iot-core/.
[129] "grpc / grpc.io." http://www.grpc.io/.
[130] "Announcing gRPC Alpha for Google Cloud Pub/Sub | Google Cloud ...." 22 Mar. 2016, https://cloud.google.com/blog/big-data/2016/03/announcing-grpc-alpha-for-google-cloud-pubsub.
[131] "Weave Compatibility Definition Document | Weave | Google Developers." 8 Mar. 2017, https://developers.google.com/weave/guides/compatibility-definition-document.
[132] "OpenWrt." https://openwrt.org/.
[133] "azure-iot-protocol-gateway/README.md at master · Azure ... - GitHub." https://github.com/Azure/azure-iot-protocol-gateway/blob/master/README.md.
[134] "Azure REST API Reference | Microsoft Docs." 22 Mar. 2017, https://docs.microsoft.com/en-us/rest/api/.
[135] "New – Just-in-Time Certificate Registration for AWS IoT | AWS Blog." 3 Aug. 2016, https://aws.amazon.com/blogs/aws/new-just-in-time-certificate-registration-for-aws-iot/.
[136] "OAuth Core 1.0." 4 Dec. 2007, https://oauth.net/core/1.0/.
[137] "Multicast DNS - Wikipedia." https://en.wikipedia.org/wiki/Multicast_DNS.
[138] "Zero-configuration networking - Wikipedia." https://en.wikipedia.org/wiki/Zero-configuration_networking.
[139] "Named pipe - Wikipedia." https://en.wikipedia.org/wiki/Named_pipe.
[140] "libcurl." https://curl.haxx.se/libcurl/.
[141] "uClibc." https://www.uclibc.org/.
[142] "GitHub - android/platform_bionic." https://github.com/android/platform_bionic.
[143] "SSL Library mbed TLS / PolarSSL: Download for free or buy a ...." https://tls.mbed.org/.
[144] "wolfSSL - Embedded SSL Library for Applications, Devices, IoT, and ...." https://www.wolfssl.com/.
[145] "musl libc." https://www.musl-libc.org/.
[146] "W25Q128FV Datasheet - Winbond." 24 Aug. 2015, https://www.winbond.com/resource-files/w25q128fv%20rev.l%2008242015.pdf.
[147] "GitHub - sprinkler/rainmachine-openwrt-os: RainMachine V2 ...." https://github.com/sprinkler/rainmachine-openwrt-os.
[148] "How Elastic Load Balancing Works - AWS Documentation." http://docs.aws.amazon.com/elasticloadbalancing/latest/userguide/how-elastic-load-balancing-works.html.
[149] "SSL Offloading | Array Networks." https://www.arraynetworks.com/functions-ssl-offloading.html.
[150] "Node.js." https://nodejs.org/.
[151] "Express.js." https://expressjs.com/.
[152] "GitHub - nodejitsu/node-http-proxy: A full-featured http proxy for node.js." https://github.com/nodejitsu/node-http-proxy.
[153] "GitHub - mysqljs/mysql: A pure node.js JavaScript Client implementing ...." https://github.com/mysqljs/mysql.
[154] "GitHub - NodeRedis/node_redis: redis client for node." https://github.com/NodeRedis/node_redis.
[155] "GitHub - winstonjs/winston: a multi-transport async logging library for ...." https://github.com/winstonjs/winston.
[156] "What is time-to-live (TTL)? - Definition from WhatIs.com." 30 Nov. 2015, http://searchnetworking.techtarget.com/definition/time-to-live. Accessed 27 Jun. 2017.
[157] "NGINX Wiki" https://wiki.nginx.org/.
[158] "t2.small - Amazon S3 - Amazon Web Services." 22 Oct. 2015, https://s3.amazonaws.com/cloudharmony/iperf_1_0/aws:ec2/t2.small/us-west-1/2015-10-22/5573/760779-1/report.pdf.
[159] "IP sysctl - Kernel.org." https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt.
[160] "OAuth Community Site." https://oauth.net/.
[161] "Add OAuth Authentication to Exposed REST APIs - OutSystems." 15 Dec. 2015, https://www.outsystems.com/forums/discussion/16906/add-oauth-authentication-to-exposed-rest-apis/.
[162] "Fisher-Yates shuffle - ALG Programming-Algorithms.net." http://www.programming-algorithms.net/article/43676/Fisher-Yates-shuffle.
[163] "AWS | Elastic Load Balancing - Cloud ...." https://aws.amazon.com/elasticloadbalancing/.
[164] "RFC 7230 - Hypertext Transfer Protocol (HTTP/1.1 ... - IETF Tools." https://tools.ietf.org/html/rfc7230.
[165] "HTTP: HTTP/1.X - High Performance Browser Networking (O'Reilly)." https://hpbn.co/http1x/.
[166] "performance · Issue #1058 · nodejitsu/node-http-proxy · GitHub." https://github.com/nodejitsu/node-http-proxy/issues/1058.
[167] "Networking 101: Building Blocks of TCP - High Performance Browser ...." https://hpbn.co/building-blocks-of-tcp/.
[168] "RFC 2616 - IETF." https://www.ietf.org/rfc/rfc2616.txt.
[169] "REST Best Practices: Managing Concurrent Updates - 4PSA Blog." 3 Apr. 2013, https://blog.4psa.com/rest-best-practices-managing-concurrent-updates/.
[170] “Microsoft Edge platform status”, https://developer.microsoft.com/en-us/microsoft-edge/platform/status/serversenteventseventsource/.
[171] "GitHub - websockets/ws: Simple to use, blazing fast and thoroughly ...." https://github.com/websockets/ws.